Hello there!
I bet I do something wrong, but after couple of days I’m close to giving up. I try to implement a model described in the following paper: Real-time CNN for Emotion and gender classification. Authors also have implemented the proposed model using Keras. So, I used their implementation as a reference to verify my model. My implementation below:
class MiniXception(nn.Module):
def __init__(self):
super(MiniXception, self).__init__()
self.beginning = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, stride=1, bias=False),
nn.BatchNorm2d(8, eps=1e-03),
nn.ReLU(),
nn.Conv2d(in_channels=8, out_channels=8, kernel_size=3, stride=1, bias=False),
nn.BatchNorm2d(8),
nn.ReLU()
)
self.core = nn.ModuleList([
nn.ModuleDict({
'separable': nn.Sequential(
SeparableConv2d(in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=16),
nn.ReLU(),
SeparableConv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=16),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
),
'residual': nn.Sequential(
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=1, stride=2, padding=0, bias=False),
nn.BatchNorm2d(num_features=16)
)
}),
nn.ModuleDict({
'separable': nn.Sequential(
SeparableConv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=32),
nn.ReLU(),
SeparableConv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=32),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
),
'residual': nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=1, stride=2, padding=0, bias=False),
nn.BatchNorm2d(num_features=32)
)
}),
nn.ModuleDict({
'separable': nn.Sequential(
SeparableConv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
SeparableConv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
),
'residual': nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=1, stride=2, padding=0, bias=False),
nn.BatchNorm2d(num_features=64)
)
}),
nn.ModuleDict({
'separable': nn.Sequential(
SeparableConv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
SeparableConv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(num_features=128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
),
'residual': nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=2, padding=0, bias=False),
nn.BatchNorm2d(128)
)
})
])
self.final = nn.Sequential(
nn.Conv2d(128, 7, 3),
GlobalAvgPooling2d(),
nn.Softmax(dim=1)
)
def initialize(m):
if isinstance(m, nn.Conv2d):
nn.init.kaiming_uniform_(m.weight)
self.beginning.apply(initialize)
self.core.apply(initialize)
self.final.apply(initialize)
def forward(self, x):
out = self.beginning(x)
for m in self.core:
out_sep = m['separable'](out)
out_res = m['residual'](out)
out = out_sep + out_res
out = self.final(out)
return out
class GlobalAvgPooling2d(nn.Module):
def __init__(self):
super(GlobalAvgPooling2d, self).__init__()
def forward(self, x):
return torch.mean(x, (2, 3))
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, bias=False):
super(SeparableConv2d, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels,
out_channels=in_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=in_channels,
bias=bias)
self.point_wise = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=bias)
def forward(self, x):
x = self.conv1(x)
x = self.point_wise(x)
return x
Training routine:
def train(model, train_loader, test_loader, num_epochs, criterion, optimizer, scheduler):
loss_history = []
acc_history = []
best = float('inf')
# batch size = 32 as it is in the original implementation
for epoch in range(num_epochs):
loss_val = 0.0
for batch_idx, sample in enumerate(train_loader):
x, y = sample[0], sample[1]
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
loss_val += loss.item()
accuracy = __validate__(model, test_loader)
scheduler.step(loss_val)
loss_history.append(loss_val)
acc_history.append(accuracy)
return loss_history, acc_history
def __validate__(model, data_loader):
correct = 0
total = 0
with torch.no_grad():
for batch_index, sample in enumerate(data_loader):
x, y = sample[0], sample[1]
outputs = model(x)
_, predicted = torch.max(outputs.data, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
accuracy = 100 * correct / total
return accuracy
...
# transforms applied to images from fer2013 dataset
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485], [0.229])])
optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr_init, eps=1e-07)
criterion = torch.nn.CrossEntropyLoss(reduction='mean')
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode=self.scheduler_mode,
patience=self.patience,
verbose=True)
...
I will post complete summaries on demad, here I suggest looking at the resume for both:
[Keras]
Total params: 58,423
Trainable params: 56,951
Non-trainable params: 1,472
[Torch]
Total params: 56,951
Trainable params: 56,951
Non-trainable params: 0
As we can see, original implementation has 1,472 non-trainable params. Going through layers I found, that keras BatchNorm has 2x params comparing to pytorch BatchNorm layer. I don’t yet understand why, though.
So far I’ve tried to reduce my dataset to only 10 samples and get loss=0, but it gets stuck around 1.16 and never goes down. Here is a plot:
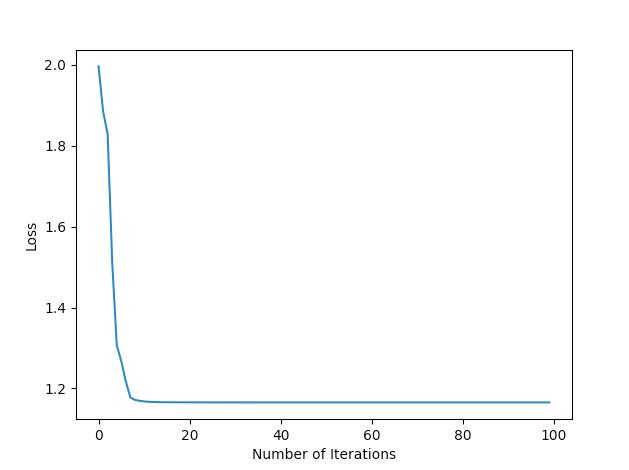
Learning on full dataset results in ~1.3 loss value with zero to no changes after 300 epoch. Is there something I do obviously wrong here?
Any help is appreciated, sorry for such a wall of text, not sure which information is crucial yet.
UPD:
Difference between # of parameters in keras and pytorch BatchNorm explained here: python - Difference between Keras' BatchNormalization and PyTorch's BatchNorm2d? - Stack Overflow