Dear All,
I’m trying to re-implement this code goturn in PyTorch.
Though I have tried to implement the PyTorch code just as is Caffe code with minor changes. I couldn’t figure out why I see poor convergence in PyTorch.
I would really appreciate any help if you could share what might be going wrong or if I’m missing.
I apologize for the long description.
Just to clear out what I have done compared to Caffe implementation. I will describe in detail.
Network architecture and weights
I have defined a CaffeNet architecture and weights just as in network.prototxt
class CaffeNetArch(nn.Module):
"""Docstring for AlexNet. """
def __init__(self, num_classes=1000):
"""This defines the caffe version of alexnet"""
super(CaffeNetArch, self).__init__()
self.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.LocalResponseNorm(5, alpha=0.0001, beta=0.75),
# conv 2
nn.Conv2d(96, 256, kernel_size=5, padding=2, groups=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.LocalResponseNorm(5, alpha=0.0001, beta=0.75),
# conv 3
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# conv 4
nn.Conv2d(384, 384, kernel_size=3, padding=1, groups=2),
nn.ReLU(inplace=True),
# conv 5
nn.Conv2d(384, 256, kernel_size=3, padding=1, groups=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2))
def transfer_weights(model, pretrained_model_path, dbg=False):
weights_bias = np.load(pretrained_model_path, allow_pickle=True,
encoding='latin1').item()
layer_num = 0
with torch.no_grad():
for layer in model.modules():
if type(layer) == torch.nn.modules.conv.Conv2d:
layer_num = layer_num + 1
key = 'conv{}'.format(layer_num)
w, b = weights_bias[key][0], weights_bias[key][1]
layer.weight.copy_(torch.from_numpy(w).float())
layer.bias.copy_(torch.from_numpy(b).float())
if dbg:
layer_num = 0
for layer in model.modules():
if type(layer) == torch.nn.modules.conv.Conv2d:
layer_num = layer_num + 1
key = 'conv{}'.format(layer_num)
w, b = weights_bias[key][0], weights_bias[key][1]
assert (layer.weight.detach().numpy() == w).all()
assert (layer.bias.detach().numpy() == b).all()
def CaffeNet(pretrained_model_path=None):
"""Alexenet pretrained model
@pretrained_model_path: pretrained model path for initialization
"""
model = CaffeNetArch().features
if pretrained_model_path:
transfer_weights(model, pretrained_model_path)
return model
I use the same weights as in Caffe and transfer the weights and the rest of the FC layers are initialized just with the same weights as it is done in Caffe. ( I have dumped the initialized weights and assigned it here)
def __init__(self, pretrained_model=None,
init_fc='/home/nthere/2020/pytorch-goturn/src/scripts/fc_init.npy', num_output=4):
""" """
super(GoturnNetwork, self).__init__()
# self._net = AlexNet(pretrained_model_path=pretrained_model)
self._net = CaffeNet(pretrained_model_path=pretrained_model)
self._classifier = nn.Sequential(nn.Linear(256 * 6 * 6 * 2, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, num_output))
self._num_output = num_output
if init_fc:
self._init_fc = init_fc
self._caffe_fc_init()
else:
self.__init_weights()
def _caffe_fc_init(self):
"""Init from caffe normal_
"""
wb = np.load(self._init_fc, allow_pickle=True).item()
layer_num = 0
with torch.no_grad():
for layer in self._classifier.modules():
if isinstance(layer, nn.Linear):
layer_num = layer_num + 1
key_w = 'fc{}_w'.format(layer_num)
key_b = 'fc{}_b'.format(layer_num)
w, b = wb[key_w], wb[key_b]
w = np.reshape(w, (w.shape[1], w.shape[0]))
b = np.squeeze(np.reshape(b, (b.shape[1],
b.shape[0])))
layer.weight.copy_(torch.from_numpy(w).float())
layer.bias.copy_(torch.from_numpy(b).float())
Network initialization is exactly as in Caffe. Then the learning rate for each of the layers and the weight decay for frozen layers are the same as in Caffe. This is ensured in this code below:
def __set_lr(self):
'''set learning rate for classifier layer'''
param_dict = []
if 1:
conv_layers = self._model._net
for layer in conv_layers.modules():
if type(layer) == torch.nn.modules.conv.Conv2d:
param_dict.append({'params': layer.weight,
'lr': 0,
'weight_decay': self.hparams.wd})
param_dict.append({'params': layer.bias,
'lr': 0,
'weight_decay': 0})
regression_layer = self._model._classifier
for layer in regression_layer.modules():
if type(layer) == torch.nn.modules.linear.Linear:
param_dict.append({'params': layer.weight,
'lr': 10 * self.hparams.lr,
'weight_decay': self.hparams.wd})
param_dict.append({'params': layer.bias,
'lr': 20 * self.hparams.lr,
'weight_decay': 0})
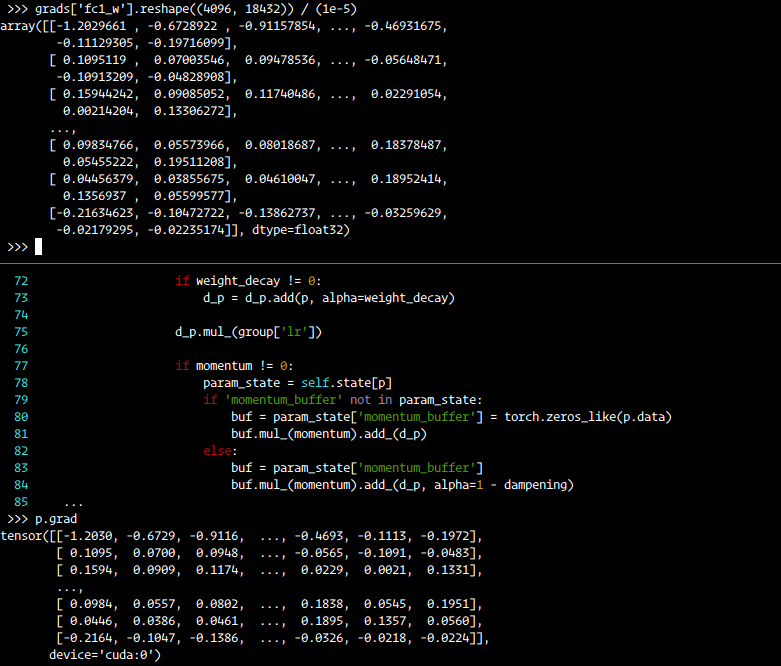
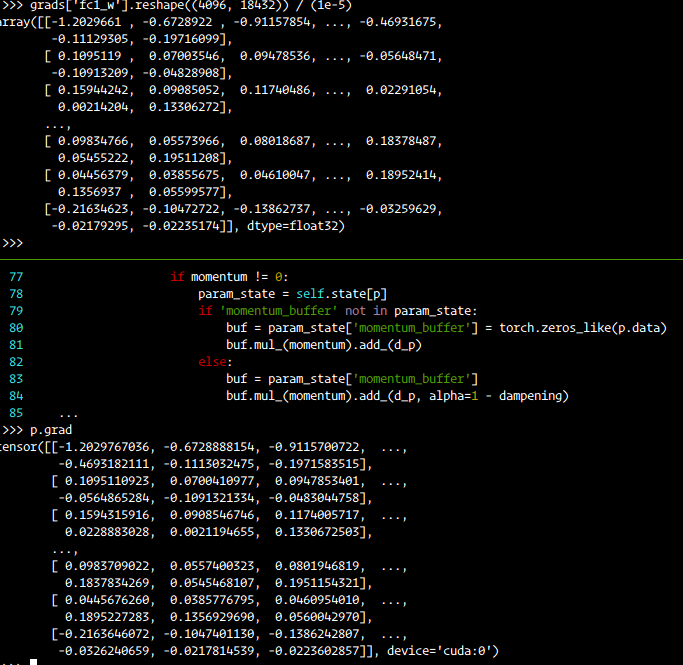
In terms of the loss function, Caffe doesn’t average over batch size, So I used size_average=False in loss = torch.nn.L1Loss(size_average=False)(pred_bb, gt_bb.float())
I even modified the PyTorch SGD to be as same as Caffe SGD as mentioned here
and the optimizers are configured as below: lr = 1e-06 and momentum=0.9 and gamma=0.1, step_size=1 (where as in caffe number of steps is number of iteration which is set to 100000)
optimizer = CaffeSGD(params,
lr=self.hparams.lr,
momentum=self.hparams.momentum,
weight_decay=self.hparams.wd
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=self.hparams.lr_step, gamma=self.hparams.gamma
Debugging
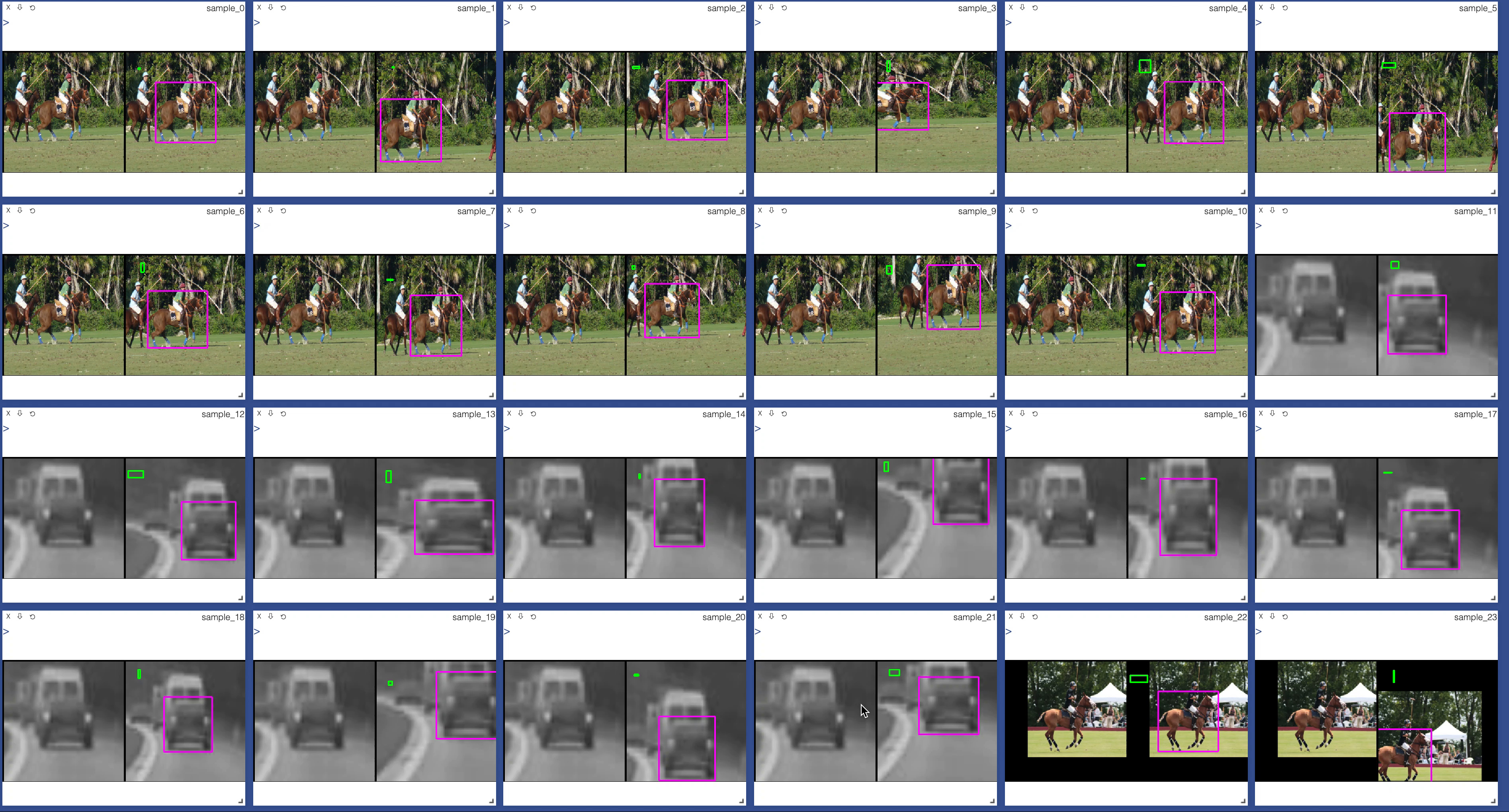
To compare the implementation, I turned off the dropout (setting p=0) and verified two iterations of the forward and backward pass with weight update. Both Caffe and PyTorch with the above code gave the same loss and weight updates.
Following are the minor changes
- Caffe uses a batch size of 50, whereas due to the way I have implemented dataloader, I use a batch size of 44. I hope this shouldn’t matter.
- Random augmentations are done for each frame to move the bounding box using uniform random distribution. (I have used torch random number generator with num_workers=6) I have plotted the random number generated outputs and found them to be uniform and non-repetative for a single batch.
Following are the differences in PyTorch vs Caffe
Random number generation is different. And the dropout of activations is different. These shouldn’t be the issue as my understanding.
Do you think I’m missing something here? Let me know if you need more input to analyze this issue.
I look forward to the discussion and help.