Hello everyone,
I struggle to understand the details of the Inception_v3 implementation in PyTorch. It seems to me that there are some differences between the documentation and the actual implementation. Could someone confirm that there are differences ? If so, is there somewhere a schema to help understand what happens under the hood ?
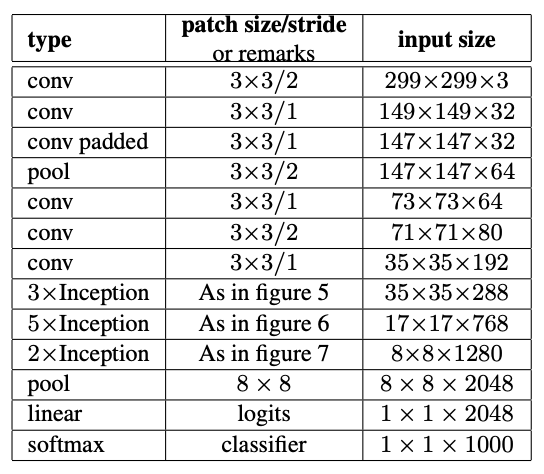
I attached the table you can find on Inception_v3 | PyTorch as well as in the original paper. The implementation I consider is here: vision/torchvision/models/inception.py at main · pytorch/vision · GitHub
For example I don’t see any equivalence of the layer ‘self.Conv2d_3b_1x1’ in the table.