Hello ! ![]()
I have some questions to ask about this implementation below :
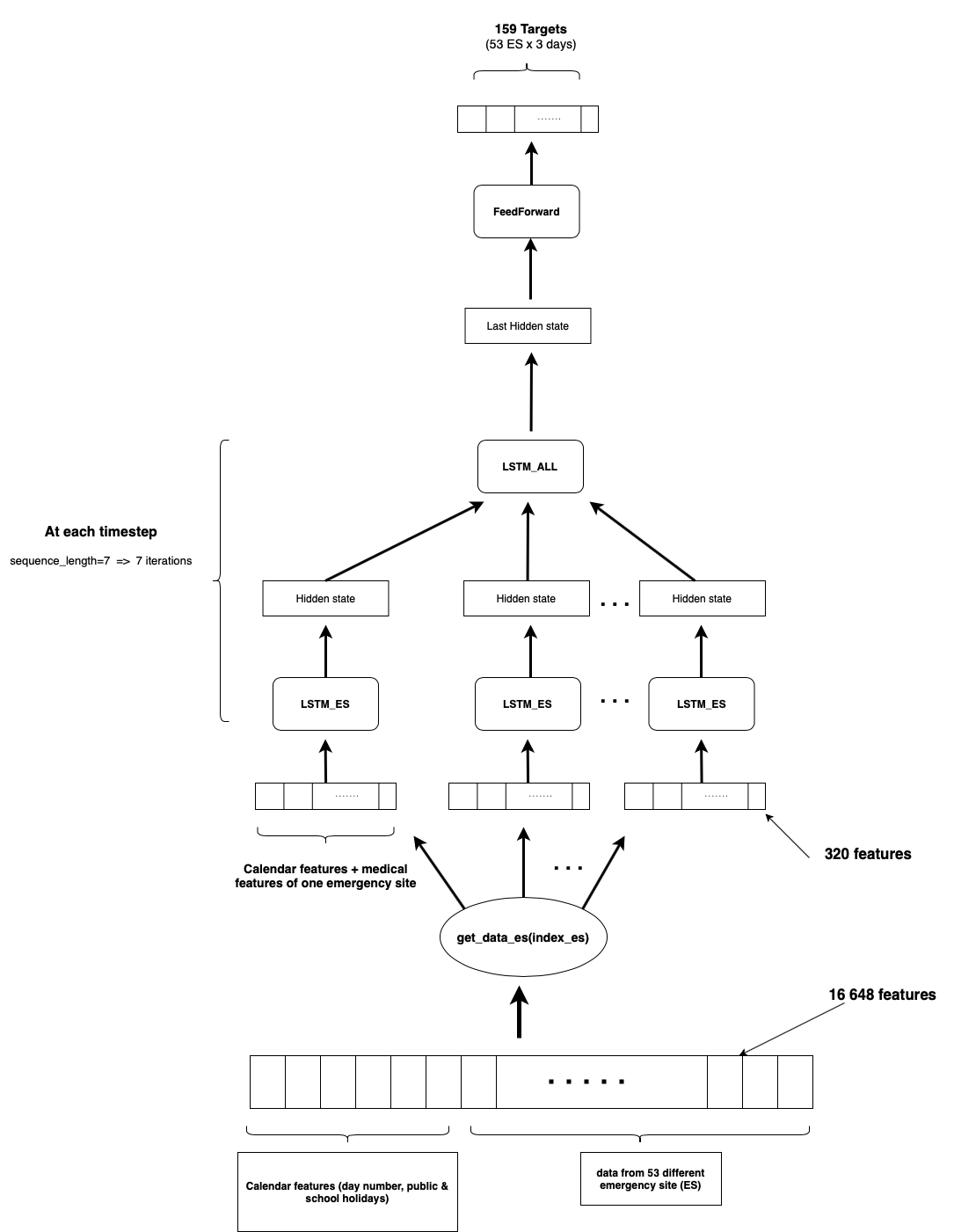
As you can see it looks like a Sequence-to-one model, but in this case I have multiple and distinct LSTMs in the encoding part, each LSTM processes a part of the multivariate time series data I have in the input, and all the hidden states of these multiple LSTMs are concatenated and given as an input to the LSTM_ALL , and since I have a regression problem in this case I used the MAE Loss to train the model.
My questions are :
1- is this implementation of the 53 independent LSTMs is correct :
self.list_lstm_su = nn.ModuleList(
[
nn.LSTM(
self.input_dim_su,
hidden_dim_su,
layer_dim_su,
batch_first=True,
dropout=dropout,
)
for _ in range(53)
]
)
2- If that’s correct, does this procedure below will work properly in the forward method and not cause some problems during backprop :
concat_hidden_states = torch.zeros(x.size(0),7, self.hidden_dim_su
for i, lstm in enumerate(self.list_lstm_su):
concat_result = torch.cat(
(embed_days, x[:, :, np.r_[3:8, 8 + (i * 314) : 8 + (i + 1) * 314]]), 2
)
concat_result = concat_result.float()
out, _ = lstm(
concat_result,
(h0_su.detach(), c0_su.detach()),
)
concat_hidden_states = torch.cat((concat_hidden_states, out), 2)
3- My last question is about the implementation itself, I think that this loss function doesn’t reflect the problem I’m trying to optimize, because as you can see in the architecture, the target is composed of 159 values, each 3 successive value comes actually from one of the LSTMs in the encoding part so if let’s say I have a predicted vector where 158 values are equal to the ones in the label, my error loss is still not equal to zero and the error will backpropagate through all the LSTMs but actually only one LSTM is doing something wrong, because I still need one value to be equal to the one in label.
Thank you very much for your help ![]()
![]()