I am trying to implement DeepLab V3+ in PYTORCH, but I am confused in some parts of the network.
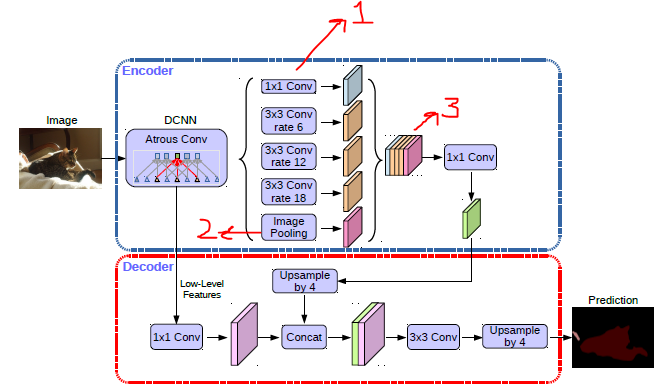
Is “1*1 conv” -. Global Average Pooling as mentioned in DeepLab V3
What exactly is “Image Pooling” operation?
As Dilated convolutions of different Rates are applied on the same feature map, the resulting feature map will have different dimensions. Is padding applied during these convolutions, so that the final results can be concatenated?
The “Image Pooling” is the Global Average Pooling.
the dilations do not result in different dimensions but you need to have different padding for each.
Let me go into a little more detail for the padding issue. For a normal NxN-Conv (dilation rate=1) choosing a padding of (N-1)//2 will give you the same size output as input. Now consider the a 3x3 Conv with dilation rate=2. Draw a little picture and you can convince yourself that the field of view is the same as the field of view for a 5x5 Conv and therefore, the padding required to have the same size output as input is not (3-1)//2=1, as with the rate=1 case, but rather (5-1)//2=2
It turns out that the generalized formula for “same” padding for atrous convs is