im implementing classification with LBP on Artificial Neural Network, here i provide my custom dataset and pipeline code.
custom dataset
class getLBPDataset(Dataset):
def __init__(self, data, filter, nPoints, method='ror',transform=None):
self.data = data
self.transform = transform
self.filter = filter
self.nPoints = nPoints
self.method = method
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
im = self.data[idx][0]
label = self.data[idx][1]
binPoints = self.filter * self.nPoints
totensor = transforms.Compose([transforms.ToTensor(), transforms.Normalize((19.0818,), (7.6182,)), lambda x: x.numpy().transpose((1,2,0)), lambda x: x[:,:,0]])
if self.transform:
im = self.transform(im)
lbp = local_binary_pattern(im, binPoints, self.filter, self.method)
lbpN = totensor(lbp)
return (lbpN, label)
Pipeline
dataset = dt.ImageFolder(root=dsPath)
datasetSize = len(dataset)
splitSize = {
'train' : int((trainSplit*datasetSize)+1),
'val' : int((valSplit*datasetSize)),
'test' : int((testSplit*datasetSize))
}
trainDataset, valDataset, testDataset = random_split(dataset, [splitSize['train'], splitSize['val'], splitSize['test']])
trainT = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(3),
transforms.Resize(size=(imH, imW)),
transforms.Normalize(mean=[0.6933, ], std=[0.3887, ]),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(10),
lambda x : x.numpy().transpose((1,2,0)),
lambda x : x[:,:,0]
])
valT = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(3),
transforms.Resize(size=(imH, imW)),
transforms.Normalize(mean=[0.6933, ], std=[0.3887, ]),
lambda x : x.numpy().transpose((1,2,0)),
lambda x : x[:,:,0]
])
testT = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(3),
transforms.Resize(size=(imH, imW)),
transforms.Normalize(mean=[0.6933, ], std=[0.3887, ]),
lambda x : x.numpy().transpose((1,2,0)),
lambda x : x[:,:,0]
])
LBPDataset = {
'train' : getLBPDataset(trainDataset, lbpFilter, lbpBinPoints, method='uniform', transform=trainT),
'val' : getLBPDataset(valDataset, lbpFilter, lbpBinPoints, method='uniform', transform=valT),
'test' : getLBPDataset(testDataset, lbpFilter, lbpBinPoints, method='uniform', transform=testT)
}
LBPLoad = {
'train' : DataLoader(LBPDataset['train'], batch_size=batchSize, num_workers=2, shuffle=True),
'val' : DataLoader(LBPDataset['val'], batch_size=batchSize, num_workers=2, shuffle=True),
'test' : DataLoader(LBPDataset['test'], batch_size=batchSize, num_workers=2, shuffle=True)
}
as you can see above maybe you guys think i’ve shallow experience on computer vision, and that is true so i don’t really know if my implementation is correct or not. After all those process was done, next i feed the extracted image from LBP to my model and do the training which look like this
class ANN(nn.Module):
def __init__(self):
super(ANN, self).__init__()
self.dense1 = nn.Linear(10000, 4096)
self.dense2 = nn.Linear(4096, 2048)
self.dense3 = nn.Linear(2048, 1024)
self.dense4 = nn.Linear(1024, 512)
self.dense5 = nn.Linear(512, 128)
self.dense6 = nn.Linear(128, 64)
self.dense7 = nn.Linear(64, len(classNames))
def forward(self, x):
x = torch.flatten(x, 1)
x = F.relu(self.dense1(x))
x = F.relu(self.dense2(x))
x = F.relu(self.dense3(x))
x = F.relu(self.dense4(x))
x = F.relu(self.dense5(x))
x = F.relu(self.dense6(x))
x = F.relu(self.dense7(x))
return x
ann = ANN()
ann.to(device)
summary(ann, (imH, imW))
Training Function
def trainModel(model, criterion, optimizer, scheduler=None, epochs=10):
T = time.time()
epochLog = []
tLossLog = []
tAccLog = []
vLossLog = []
vAccLog = []
bestModel = copy.deepcopy(model.state_dict())
bestAcc = .0
for epoch in range(epochs):
print(f'Epoch {epoch+1}/{epochs}')
print('-' * 10)
for phase in ['train', 'val']:
tEpoch = time.time()
if phase =='train':
model.train()
else:
model.eval()
runningLoss = .0
runningCorrect = 0
for images, labels in LBPLoad[phase]:
inputs = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs.float())
_, pred = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
runningLoss += loss.item() * inputs.size(0)
runningCorrect += torch.sum(pred == labels.data)
if phase == 'train' and scheduler:
scheduler.step()
epochLoss = runningLoss / size[phase]
epochAcc = runningCorrect.double() / size[phase]
epochLog.append(epoch)
if phase == 'train':
tAccLog.append(epochAcc)
tLossLog.append(epochLoss)
elif phase == 'val':
vAccLog.append(epochAcc)
vLossLog.append(epochLoss)
elapsedEpoch = time.time()-tEpoch
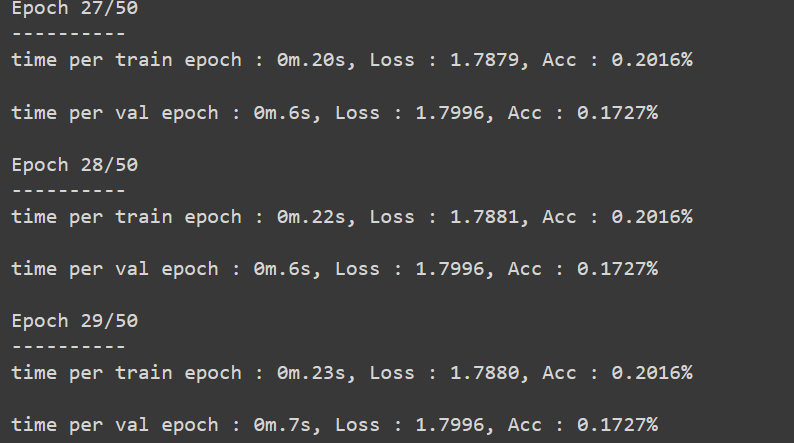
print(f'time per {phase} epoch : {elapsedEpoch//60:.0f}m.{elapsedEpoch%60:.0f}s, Loss : {epochLoss:.4f}, Acc : {epochAcc:.4f}%')
if phase=='val' and epochAcc>bestAcc:
bestAcc=epochAcc
bestModel = copy.deepcopy(model.state_dict())
print()
timeElapsed = time.time() - T
print(f'Training complete in {timeElapsed//60:.0f}m {timeElapsed%60:.0f}s')
print(f'best accuracy in : {bestAcc:.4f}%')
return (epochLog, tAccLog, tLossLog, vAccLog, vLossLog, model)
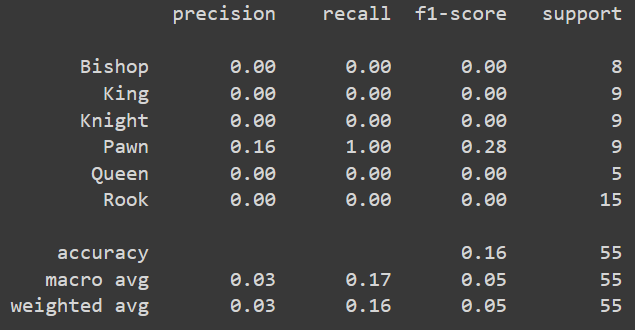
I use Adam as optimizer with 0.01 learning rate and crossentropy as criterion, and here comes the problem. In the training process the loss and accuracy was not changing at all(stuck)
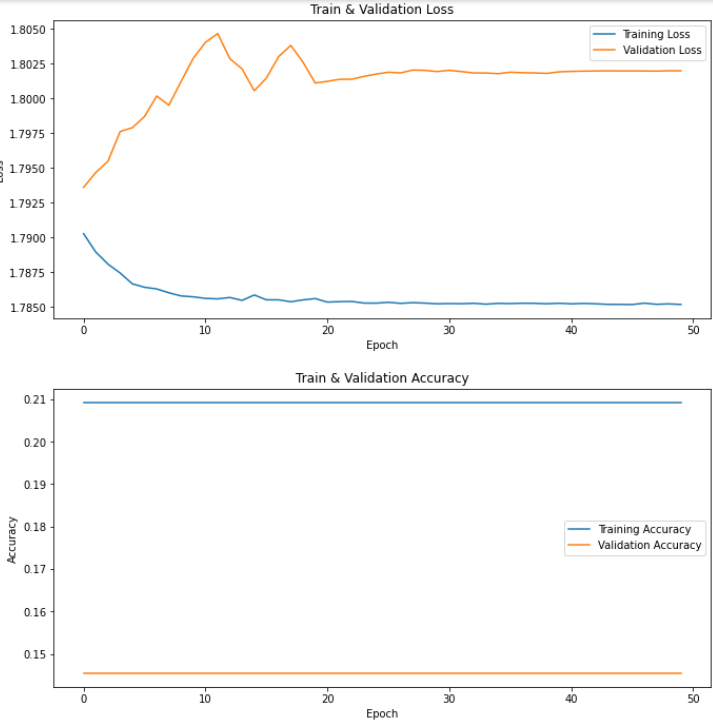
i’ve already tried SGD and RMSprop as optimizer also i change the learning rate between 0.01 - 0.00001 and i use scheduler on 20 steps with gamma = 0.1 and there’s still no big different. So my question is, is this really how we use feature extractor with ANN? if yes, then why i got a bad performance? is there anything i can do to achieve better performance?
in case needed
batch size = 32
image width and height = 100
total dataset size = 552