Hello every one. I have some question that I think are more related with Deep-Learning in general than it is with Pytorch. I think they are pretty simple, any opinion is welcome.
I am dealing with a problem where I use a segmentation network, and based on the segmentation I apply some simple rules and make a binary classification. What I am trying to do is to train a classification network that does the binary classification at once.
The advantage would be that the classification network is smaller and faster, it is easier to increase the dataset, and the post-processing isn’t necessary.
The disadvantage is that classification network usually need more data to get better generalization.
At the moment my segmentation dataset has 3000 images, and the classification has 33000 images. Just a small intersection of those images have both types of ground truth.
The issues I am facing is that the segmentation model generalizes better for new data (data that isn’t in any of my datasets. Training, validation and testing datasets), and the classification is struggling with new data.
What I want to do is to try multi-task learning, hopping that the segmentation task will help the classification task to “understand the images correctly”, getting this way a better generalization.
How exactly can this training be done? I can think in some ways, but I don’t know exactly the consequences of each approach. If someone could give some hints or help me to understand the nuances of each approach, I would be very grateful.
Here are the approaches I think:
- If my entire dataset had ground truth for both tasks, I would simply train this way:
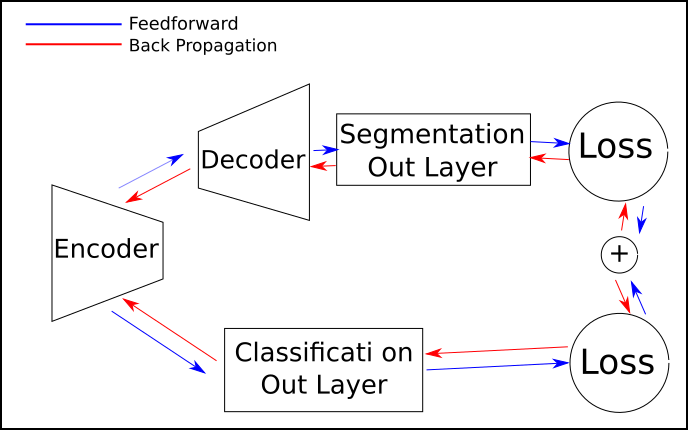
- Since only a small intersection of my dataset has both ground truth, I will have to switch between tasks. This way:
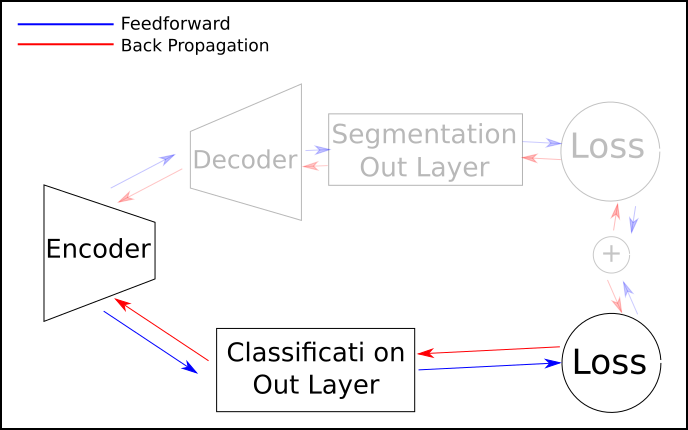
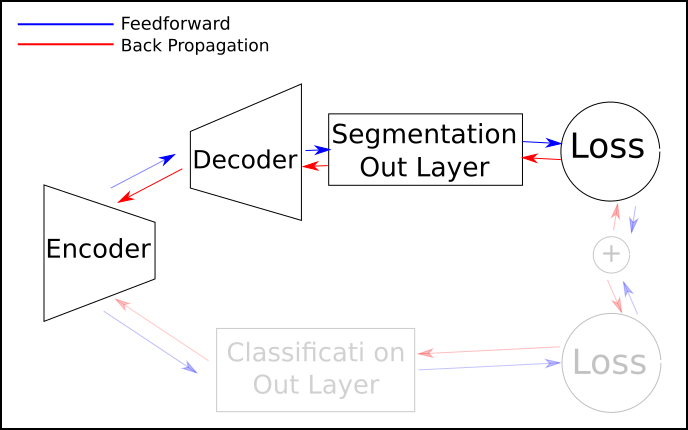
But how exactly I do it? Train one entire epoch on segmentation dataset, then one epoch on the segmentation? Should I keep bouncing with one batch of classification and then one of segmentation? Should I feed one batch of classification, keep the loss, then feed another different batch of segmentation (different images), sum the losses and then backpropagate?
I think some approaches will require more GPU memory than the others, requiring me to use smaller batch sizes.
Thank you so much for everyone that spent the the time to read this huge topic.
I will try some of these approaches and will share my finding here as well, any help is welcome.