I tried the same model on the following data without increasing the expressive power of the model, yet the model was able to learn curvature with no problem (which is strange). I needed to increase the number of epochs for the model below to learn curvature, but adding the number of epochs did not work for minimizing regression loss + Jacobian loss.
Maybe there are some hidden mistakes in how I computed the Jacobian and the gradients?
Additional things I tried:
- I tried adding 3 more layers to my model and increasing the number of neurons per layer, but nothing worked.
- I tried changing the ReLU activations to Sigmoid activations. But for Sigmoids to perform well, BatchNorm1d was needed (probably due to vanishing gradients). However, if you look at my
get_jacobianfunction, I’m passing through the network only ONE example, so BatchNorm1d would raise an error since batch-wise standard deviation can’t be calculated from a batch of one example.
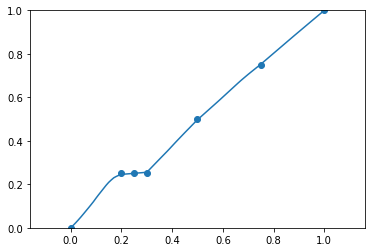
data = [0, 0.20, 0.25, 0.30, 0.5, 0.75, 1.0]
labels = [0, 0.25, 0.25, 0.25, 0.5, 0.75, 1.0]
model, opt = get_model()
jacobian_losses = []
reg_losses = []
for i in range(300):
ypred = model(torch.tensor(data).view(-1, 1).float())
loss = sos(ypred, torch.tensor(labels).view(-1, 1))
reg_losses.append(float(loss))
loss.backward()
opt.step()
opt.zero_grad()
preds = model(torch.arange(-0.1, 1.1, 0.01).view(-1, 1)).view(-1).detach().numpy()
plt.scatter(data, labels)
plt.plot(np.arange(-0.1, 1.1, 0.01), preds)
plt.ylim(0, 1)
plt.show()