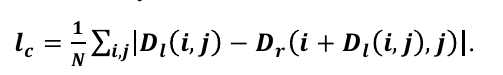I’m implementing a siamese net for depth prediction for 2 images. Both images are fed into an autoencoder, generating estimated feature map / disparity maps. Let’s label those output as d_left and d_right. I’ve came into this loss function that is used for minimizing the error.
I don’t understand it’s concept, because in the fomula above, the left disparity at index i, j is added to index i of right disparity. But that doesn’t make any sense, because disparity is a floating point number and index is an integer. If someone knows the right implementation of this, I would appreciate all help.
I mean you have 2 images which look at the same scene. Due to the separation of the lenses, an object in the right image is gonna be slightly displaced to the left compared to its position in the left image.
I think this simply tries to compensate that so the object is in the same position when you apply the loss.
So prob D_r(i+D_l) works in the continuous world. Since images are sampled, in the discrete domain you just need to round or crop that number. Maybe either cropping or rounding is one of this stupid tiny details that matters a lot but don’t have exp in the field