Thanks for the explanation
I am training for more epoch as you suggested to improve the model performance.
Due to the nature of the dataset (given as compressed .nii.gz), I converted each of the datasets to .npy in order to train the volumetric data in slices. Doing this, I split the dataset into training, validation, and testing since some of the given files are either without pathologies, with just one pathology, or both (where there is a bit overlap). Currently rerunning with a different splitting ratio of the training to validation.
This is also one of my worries on seeing the result and I have checked what might likely be the cause. I have computed the loss by initializing to zero on every epoch and followed the example given on the PyTorch site though for a classification task.
print('Training & Validation Started......')
for epoch in epoch_ranger:
start_time = time.time()
epoch_loss = {"train":{"pathologies":0, "lunglobes":0},
"valid":{"pathologies":0, "lunglobes":0}}
epoch_score = {"train":{"pathologies":0, "lunglobes":0},
"valid":{"pathologies":0, "lunglobes":0}}
epoch_channel = {"train":{}, "valid":{}}
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
model.train()
else:
model.eval()
running_pathologies_loss, running_lunglobes_loss = 0.0, 0.0
running_pathologies_score, running_lunglobes_score = 0.0, 0.0
# Iterate over data.
for data in dataloaders[phase]:
inputs, pathology_target = data
inputs = inputs.to(device)
pathology_target = pathology_target.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
pathology_loss = criterion["pathologies"](outputs, pathology_target)#.mean() # [:, [0,1,2], :,:]
pathology_pred = torch.nn.Sigmoid()(outputs) >= .5
dice_coefficient_pathologies = evaluation_metric(pathology_pred, pathology_target)
# backward + optimize only if in training phase
if phase == 'train':
pathology_loss.backward() #retain_graph=True
optimizer.step()
# statistics
running_pathologies_loss += pathology_loss.item() * inputs.size(0)
running_pathologies_score += dice_coefficient_pathologies.item() * inputs.size(0)
epoch_loss[phase]["pathologies"] = running_pathologies_loss/len(dataloaders[phase].dataset)
epoch_score[phase]["pathologies"] = running_pathologies_score / len(dataloaders[phase].dataset)
# storing experiment result for visualization
container[phase]["loss"]["pathologies"].append(epoch_loss[phase]["pathologies"])
container[phase]["score"]["pathologies"].append(epoch_score[phase]["pathologies"])
if phase == "valid":
container["learning_rate"].append([param_group['lr'] for param_group in optimizer.param_groups][0])
average_val_loss = (epoch_loss["valid"]["pathologies"] + epoch_loss["valid"]["lunglobes"])/2
# scheduler.step(average_val_loss) #ReduceOnPlateau
# scheduler.step()
# saving model checkpoint of inference and/or resuming training
checkpoint = {
'epoch': epoch + 1,
'avg_min_val_loss': average_val_loss,
'model': model,
'model_state_dict': model.state_dict(),
'optimizer': optimizer,
'optimizer_state_dict': optimizer.state_dict(),
'container': container
}
save_checkpoint(checkpoint, False, checkpoint_path, best_model_path)
if epoch != 0 and average_val_loss < avg_min_val_loss: # pathologies or lunglobes?
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(avg_min_val_loss, average_val_loss))
avg_min_val_loss = average_val_loss
save_checkpoint(checkpoint, True, checkpoint_path, best_model_path)
training_time = str(datetime.timedelta(seconds=time.time() - start_time))[:7]
print("Epoch: {}/{}".format(epoch+1, num_epochs),
"Training | pathologies - loss: {:.4f}".format(epoch_loss["train"]["pathologies"]),
"score: {:.4f}".format(epoch_score["train"]["pathologies"]),
"Validation | pathologies - loss: {:.4f}".format(epoch_loss["valid"]["pathologies"]),
"score: {:.4f}".format(epoch_score["valid"]["pathologies"]),
"|Time: {}".format(training_time))
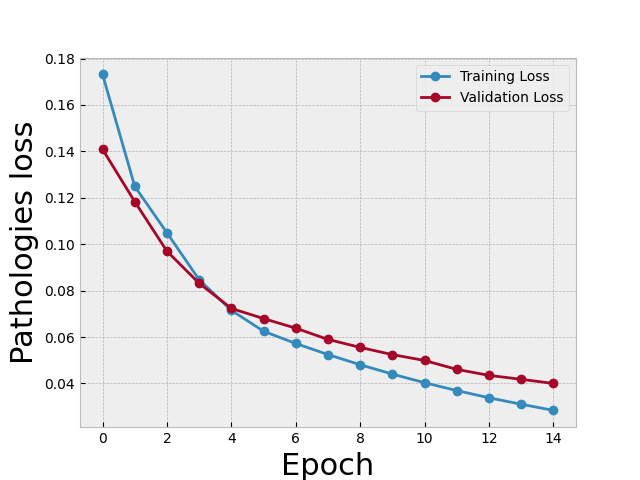
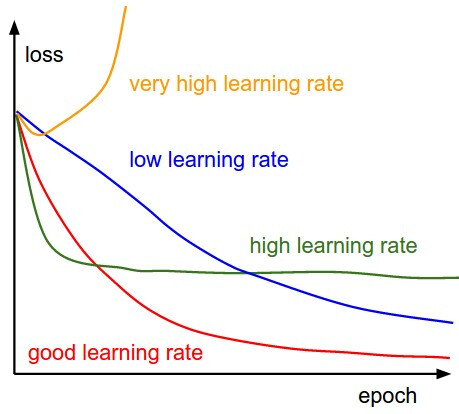
 ), you may not be able to do a lot fine tuning with your hyperparameters.
), you may not be able to do a lot fine tuning with your hyperparameters.