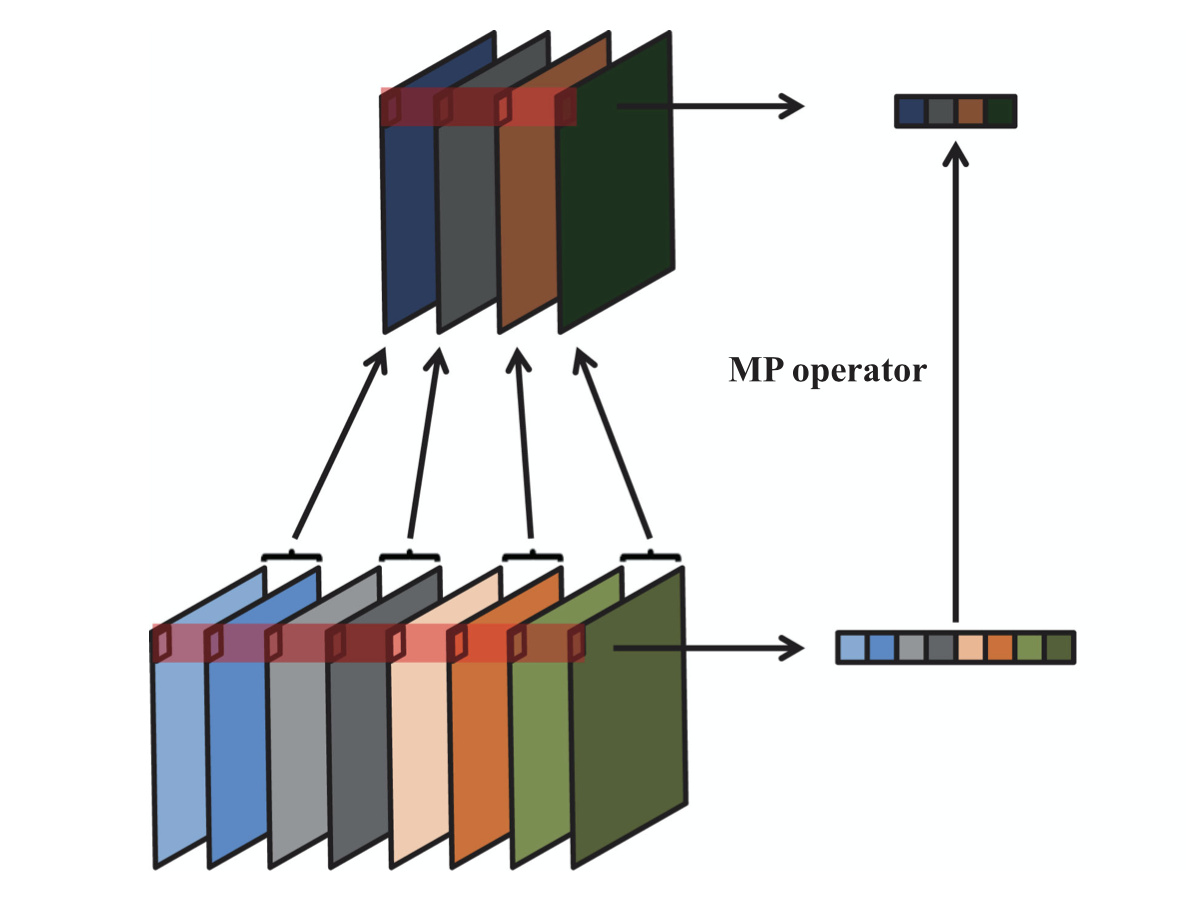
I have been working on channel pooling and have been able to recreate a method used in papers to do channel pooling instead of max pooling. Essentially the layer will take in the input, and do max pooling across the channels. The compression value, 2 in my case, will combine 2 channels and calculate the max values across each channel. This will occur to each pair of channels to create a final output. I have created the code below but I believe there must be a better way to do this which will speed up the process.
class ChannelPool(nn.MaxPool1d):
def forward(self, input):
n, c, w, h = input.size()
c = int(c/2)
output = torch.zeros(n, c, w, h).cuda()
index_pos = 0
#Compress input to output tensor
for index in range(0,input.size()[1],2):
output[0][index_pos] = torch.max(input[0][index],input[0][index+1])
index_pos +=1
return output