Hi,
I have been trying to train a LSTM on customer sequence model to predict the next event that is likely to happen.
The event space consists of 2983 events. To begin with, I have made a dataset that the most frequent 100 events form the labels for training and the last 10 events before the label as the attributes( or event sequence).
For example the event sequence in a row might be like
* Attributes : [[2,3,5,7,42,432,4,3,1,5],
[243,343,52,7,423,432,42,31,112,532]]
* Labels : [[2],
[1]]
Encoding : One-Hot encoding (For Attributes)
Raw Values (For Labels)
#Imports and defaults :
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import ast
from sklearn.model_selection import train_test_split
from datetime import datetime
import torch.nn.functional as F
from torch.optim.lr_scheduler import ReduceLROnPlateau, CyclicLR
from torch.utils import data
import matplotlib.pyplot as plt
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score, classification_report
torch.multiprocessing.set_sharing_strategy('file_system')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#HyperParameters :
sequence_length = 10
input_size = 2983
hidden_size = 1024
num_layers = 2
num_classes = 100
batch_size = 50
num_epochs = 10
learning_rate = 1
#Model :
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional = True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.randn(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.randn(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.lstm(x, (h0, c0))
out_ = self.fc(out[:, -1, :])
return out_
model = RNN(input_size, hidden_size, num_layers, num_classes).cuda()
#Loss and optimizer and Scheduler :
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum= 0.1)
scheduler = CyclicLR(optimizer, mode = 'exp_range',gamma =0.9999, base_lr= 1e-5, max_lr = 1)
#DataLoader :
class Dataset_1(data.Dataset):
def __init__(self, list_IDs, labels, n_uniq):
self.labels = labels
self.list_IDs = list_IDs
self.n_uniq = n_uniq
def __len__(self):
return len(self.list_IDs)
def __getitem__(self, index):
X = self.list_IDs[index]
X = F.one_hot(torch.from_numpy(X).to(torch.int64), num_classes = self.n_uniq)
y = self.labels[index]
return X, y
#Train and validation generators:
params = {'batch_size': 50,
'shuffle': True,
'num_workers': 30}
training_set = Dataset_1(x_train, y_train, input_size )
training_generator = data.DataLoader(training_set, **params)
validation_set = Dataset_1(x_test, y_test, input_size)
validation_generator = data.DataLoader(validation_set, **params)
#Training :
for epoch in range(10):
epoch_time = datetime.now()
# Training
print('Training Start')
counter = 0
for local_batch, local_labels in training_generator:
# Transfer to GPU
counter +=1
#local_batch, local_labels = (copy.deepcopy(local_batch), copy.deepcopy(local_labels))
local_batch, local_labels = local_batch.to(device).float(), local_labels.to(device).long()
outputs = model(local_batch)
loss= criterion(outputs,local_labels)
#loss = criterion(local_labels,outputs, input_lengths, target_lengths)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if counter%5000 == 0:
print(f"Counter : {counter} || Loss : {loss.item()}\n LR : {optimizer.state_dict()['param_groups'][0]['lr']}")
if counter%50 == 0:
lst_loss.append(loss.item())
lst_lr.append(optimizer.state_dict()['param_groups'][0]['lr'])
scheduler.step()
print(f"Epoch time : {datetime.now()-epoch_time} || Loss : {loss.item()}")
with torch.no_grad():
correct = 0
total = 0
pred = []
orig =[]
for local_batch, local_labels in validation_generator:
outputs = model(local_batch.to(device).float())
_, predicted = torch.max(outputs.data, 1)
total += local_labels.squeeze().size(0)
correct += (predicted == local_labels.squeeze().to(device).long()).sum().item()
orig.append(local_labels.squeeze().cpu().numpy())
pred.append(predicted.cpu().numpy())
if total >100000:
print(f'Epoch : {epoch}')
print('Test Accuracy of the model : {} %'.format(100 * correct / total))
pred = np.array(pred).reshape((1,-1)).squeeze()
orig = np.array(orig).reshape((1,-1)).squeeze()
s = classification_report(orig,pred)
df_eval = pd.DataFrame({'Labels' :s.split()[4:504:5],'precision' : s.split()[5:504:5] ,
'recall' :s.split()[6:504:5], 'f-1 score' : s.split()[7:504:5], 'support' : s.split()[8:504:5]})
torch.save({'model_state_dict' : model.state_dict(),
'optimizer_state_dict' : optimizer.state_dict(),
'loss' : loss.item(), 'df_eval' : df_eval,
'accuracy' : accuracy_score(orig,pred),
'epoch' : epoch
}, f'./models/epoch_test/model_top_100_LR_0.01_REDUCELR_layers_2_epoch_{epoch}_accur_{int(accuracy_score(orig,pred)*100)}.pth')
break
Below is the models Loss and Learning rate :
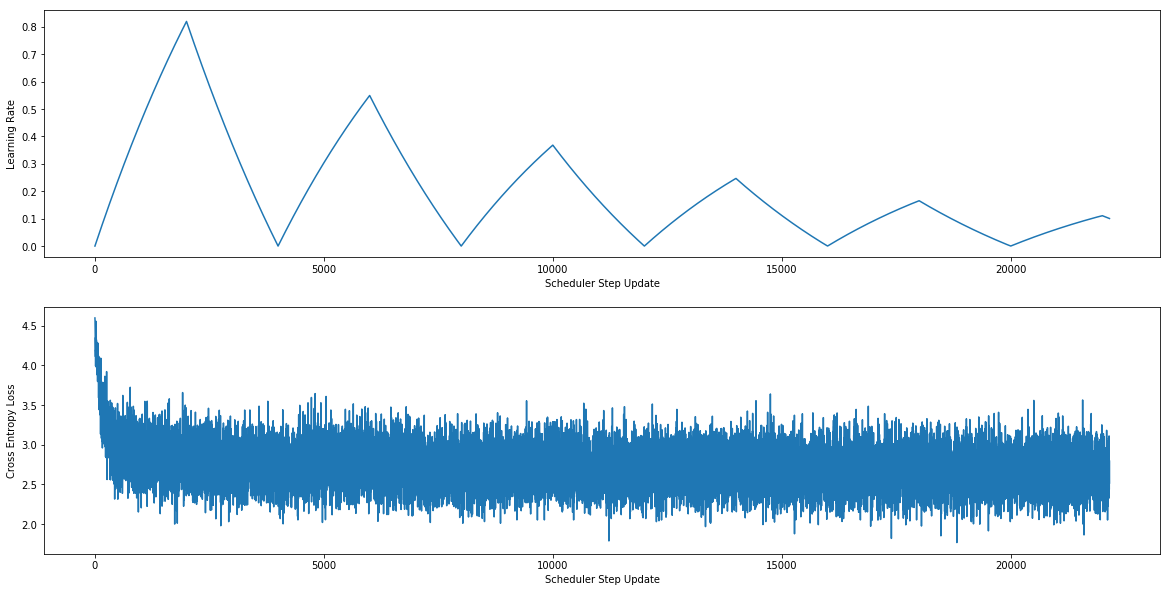
I have tried many variations of the model :
Num of layers from 1-20
hidden_size 128,1024
The dataset I used have 200M rows fro training and since the dataset is huge, with the current infra (GPU - 8GB, Memory- 700GB) that we have here it takes 15Hrs to complete 1 epoch.
The accuracy of the model in general fluctuates between 31 and 34.
Questions :
-
When the number of nodes in each layer is 128 the amount of GPU used was aroung 1GB and though increasing the batch size helps in more utilization the loss was even bigger with each iteration.
What is the range of batch sizes that I needs to look for? Is there anything in specific that is making the model take so much of time or is the time seems normal for the dataset? -
Is there any thing that I am doing that is weird and not intended to use it the way I am doing (updating LR after 1000 batches rather than for each epoch or LR range - 1e-5 to 1) ?
-
Why isn’t the loss value decreasing any further for any of the learning rates?
-
I would like to expand the model to all of the 2983 events and predict n events in the future. Is there any better algorithms and techniques that would help in achieving those?
Thanks for the help and for the resources that are being provided to make easy for the beginners to use deeplearning.
Thanks,
Swamy