Hello everyone, let me explain you a little background of my project and then I will tell you what problem I am facing so you get a clear picture of my problem.
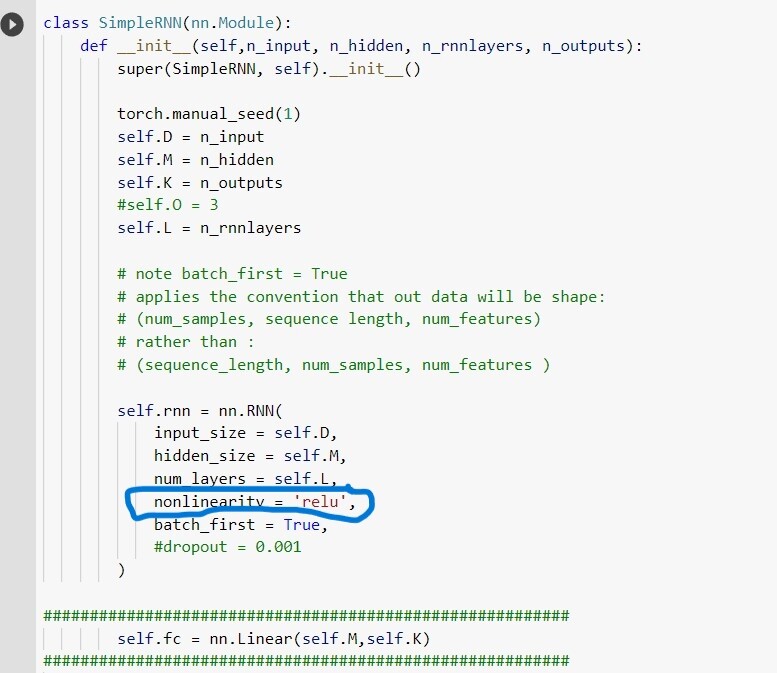
so using pytroch.nn.RNN I trained neural network with 4 input neuron, 2 hidden layers , each have 8 neurons and 2 output neurons. so I trained my RNN model and I choose relu in 'nonlinearity ’ option and everything is fine there , my results are also ok. here is the picture of my model.
(its just half code because I am not allowed to post 2 pictures)
now as per my project requirements, I had to make same RNN structure from scratch using trained weights of the above-inbuilt model and I did that but my results are not matching when I apply relu activation function as ( relu(x) = max(0,x) ). but when I use ‘Tanh’ activation in inbuilt model and use that trained weights, then my model which I made from scratch is giving similar results as inbuilt model. i know there are several types of ‘relu’ activation functions and I tried a lot to find out what relu is exactly used by inbuilt model but I couldn’t find any answer so please please anyone can tell me exactly what relu RNN module is using so that I can also use the same and get results. It will be great help as I am in last semester of my masters and I am stuck in relu.
I already seen it many times but i dont know why I am not able to run a code torch._VF.rnn_relu. even Installed many useful libraries as per suggestions by google colab but still i was getting error everytime i run this codes
See if you can follow the implementation in the example above,
if you look in the RNNBase class, it’s defined in the forward method,
_impl = _rnn_impls[self.mode]
if batch_sizes is None:
result = _impl(input, hx, self._flat_weights, self.bias, self.num_layers,
self.dropout, self.training, self.bidirectional, self.batch_first)
else:
result = _impl(input, batch_sizes, hx, self._flat_weights, self.bias,
self.num_layers, self.dropout, self.training, self.bidirectional)
see if you can follow this and get that to work, you may need to wrap torch._VF.rnn_relu within a torch.nn.Module maybe? Also, given the VF package is prefaced with an underscore it’s probably not meant to be used within the python API.
Also, if you have an error can you share the error with a minimal reproducible example?
torch._vf i guess uses in C++. also I just want some simple things but I guess you didn’t understand my problem. there is no problem in coding part nor mathematics nor implementation. its just all about I want to know what relu developers had used while building RNN module. nothing else.