Hi guys, I used multi-task model to do regression and classification.
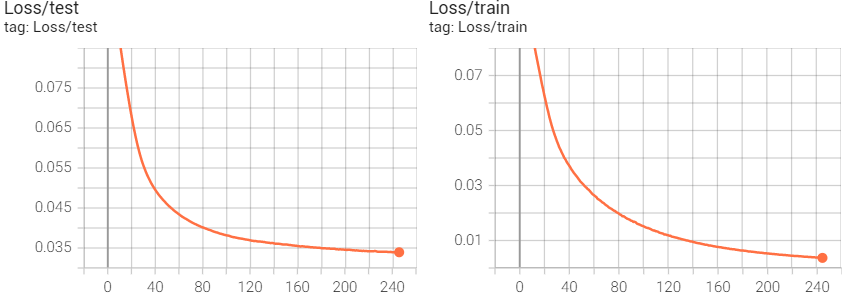
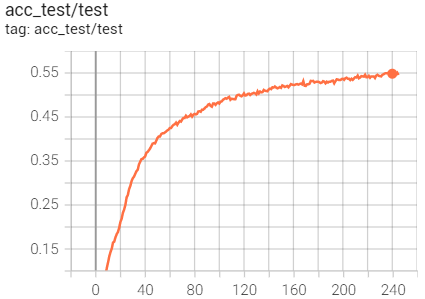
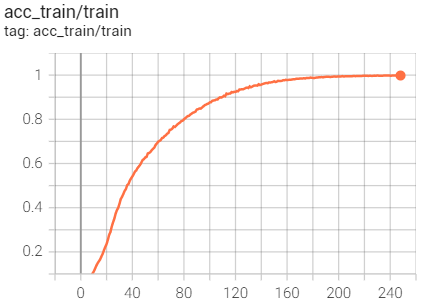
for the classification, when the training accuracy reach nearly 100%,the testing accuracy is about 50% and continued to increase. Does it mean that my model is overfitted? But the total testing loss is still decreasing?
I don’t know if there is an “official” definition of overfitting. (Maybe there
is – I just don’t know.)
But here’s how I look at it:
“Overfitting” means not just that your results (loss, accuracy, and / or
other performance metrics) are better for your training set than for
your test (or validation) set, but, furthermore, as you continue to train,
your test-set results actually get worse.
We expect the training-set results to be better – after all, the network
has already seen the training samples – so that’s okay. What we don’t
want is for the network to focus so much on “learning” specific features
of the specific samples that happen to be in the training set that it degrades
its ability to “learn” the features that are relevant to making predictions for
samples it hasn’t yet seen (such as those in the test set).
You can’t really prevent your network from learning test-set-specific
features. In isolation, I don’t call this overfitting. As long as the network
is still also learning those features relevant to your real problem, then
you’re still doing fine – at least as I see it.
So as long as your test-set loss is still going down (or other performance
metrics are still improving) with further training, you haven’t yet hit what I
would call “overfitting” (and you’re still making useful progress on the
problem you’re trying to solve).