Hello ![]() ,
,
I trained a network (tinyYoloV2) to detect person and person-like objects. But the solution isn’t really good. You can see that in the example images:
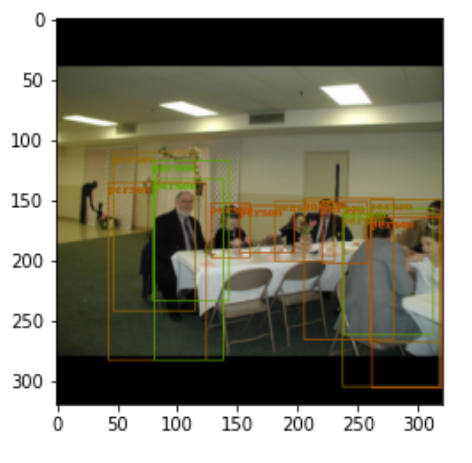
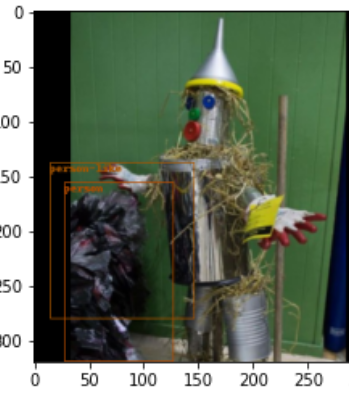
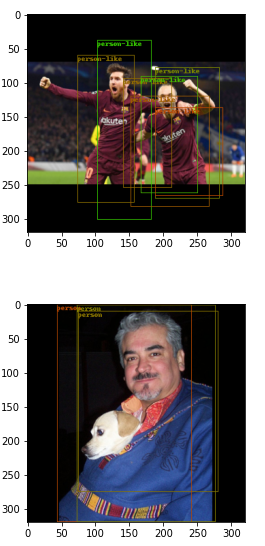
The loss from the validation data is 2.04 and from train data 1.24.
And when I train more epochs the loss decreases just very slow (for example from 1.23 to 1.22).
I tested the model with the VOC dataset and pretrained weights and it works fine.
So where can be the problem and what can I try to change to get an accurate solution at the end?
Here some of the code (classes, training):
class TinyYOLOv2(torch.nn.Module):
def __init__(
self,
num_classes=2,
anchors=(
(1.08, 1.19),
(3.42, 4.41),
(6.63, 11.38),
(9.42, 5.11),
(16.62, 10.52),
),
):
super().__init__()
# Parameters
self.register_buffer("anchors", torch.tensor(anchors))
self.num_classes = num_classes
# Layers: Anzahl 21
self.relu = torch.nn.LeakyReLU(0.1, inplace=True)
self.pool = torch.nn.MaxPool2d(2, 2)
self.slowpool = torch.nn.MaxPool2d(2, 1)
self.pad = torch.nn.ReflectionPad2d((0, 1, 0, 1))
self.norm1 = torch.nn.BatchNorm2d(16, momentum=0.1)
self.conv1 = torch.nn.Conv2d(3, 16, 3, 1, 1, bias=False)
self.norm2 = torch.nn.BatchNorm2d(32, momentum=0.1)
self.conv2 = torch.nn.Conv2d(16, 32, 3, 1, 1, bias=False)
self.norm3 = torch.nn.BatchNorm2d(64, momentum=0.1)
self.conv3 = torch.nn.Conv2d(32, 64, 3, 1, 1, bias=False)
self.norm4 = torch.nn.BatchNorm2d(128, momentum=0.1)
self.conv4 = torch.nn.Conv2d(64, 128, 3, 1, 1, bias=False)
self.norm5 = torch.nn.BatchNorm2d(256, momentum=0.1)
self.conv5 = torch.nn.Conv2d(128, 256, 3, 1, 1, bias=False)
self.norm6 = torch.nn.BatchNorm2d(512, momentum=0.1)
self.conv6 = torch.nn.Conv2d(256, 512, 3, 1, 1, bias=False)
self.norm7 = torch.nn.BatchNorm2d(1024, momentum=0.1)
self.conv7 = torch.nn.Conv2d(512, 1024, 3, 1, 1, bias=False)
self.norm8 = torch.nn.BatchNorm2d(1024, momentum=0.1)
self.conv8 = torch.nn.Conv2d(1024, 1024, 3, 1, 1, bias=False)
self.conv9 = torch.nn.Conv2d(1024, len(anchors) * (5 + num_classes), 1, 1, 0)
def forward(self, x, yolo=True):
x = self.relu(self.pool(self.norm1(self.conv1(x))))
x = self.relu(self.pool(self.norm2(self.conv2(x))))
x = self.relu(self.pool(self.norm3(self.conv3(x))))
x = self.relu(self.pool(self.norm4(self.conv4(x))))
x = self.relu(self.pool(self.norm5(self.conv5(x))))
x = self.relu(self.slowpool(self.pad(self.norm6(self.conv6(x)))))
x = self.relu(self.norm7(self.conv7(x)))
x = self.relu(self.norm8(self.conv8(x)))
x = self.conv9(x)
if yolo:
x = self.yolo(x)
return x
def yolo(self, x):
# store the original shape of x
nB, _, nH, nW = x.shape
# reshape the x-tensor: (batch size, # anchors, height, width, 5+num_classes)
x = x.view(nB, self.anchors.shape[0], -1, nH, nW).permute(0, 1, 3, 4, 2)
# get normalized auxiliary tensors
anchors = self.anchors.to(dtype=x.dtype, device=x.device)
range_y, range_x = torch.meshgrid(
torch.arange(nH, dtype=x.dtype, device=x.device),
torch.arange(nW, dtype=x.dtype, device=x.device),
)
anchor_x, anchor_y = anchors[:, 0], anchors[:, 1]
# compute boxes.
x = torch.cat([
(x[:, :, :, :, 0:1].sigmoid() + range_x[None,None,:,:,None]) / nW, # X center
(x[:, :, :, :, 1:2].sigmoid() + range_y[None,None,:,:,None]) / nH, # Y center
(x[:, :, :, :, 2:3].exp() * anchor_x[None,:,None,None,None]) / nW, # Width
(x[:, :, :, :, 3:4].exp() * anchor_y[None,:,None,None,None]) / nH, # Height
x[:, :, :, :, 4:5].sigmoid(), # confidence
x[:, :, :, :, 5:].softmax(-1), # classes
], -1)
return x #enthält: (batch_size, num. anchors, height, width, 5+num_classes)
class YOLOLoss(torch.nn.modules.loss._Loss):
""" A loss function to train YOLO v2
Args:
anchors (optional, list): the list of anchors (should be the same anchors as the ones defined in the YOLO class)
seen (optional, torch.Tensor): the number of images the network has already been trained on
coord_prefill (optional, int): the number of images for which the predicted bboxes will be centered in the image
threshold (optional, float): minimum iou necessary to have a predicted bbox match a target bbox
lambda_coord (optional, float): hyperparameter controlling the importance of the bbox coordinate predictions
lambda_noobj (optional, float): hyperparameter controlling the importance of the bboxes containing no objects
lambda_obj (optional, float): hyperparameter controlling the importance of the bboxes containing objects
lambda_cls (optional, float): hyperparameter controlling the importance of the class prediction if the bbox contains an object
"""
def __init__(
self,
anchors=(
(1.08, 1.19),
(3.42, 4.41),
(6.63, 11.38),
(9.42, 5.11),
(16.62, 10.52),
),
seen=0,
coord_prefill=12800,
threshold=0.6,
lambda_coord=1.0,
lambda_noobj=1.0,
lambda_obj=5.0,
lambda_cls=1.0,
):
super().__init__()
if not torch.is_tensor(anchors):
anchors = torch.tensor(anchors, dtype=torch.get_default_dtype())
else:
anchors = anchors.data.to(torch.get_default_dtype())
self.register_buffer("anchors", anchors)
self.seen = int(seen+.5)
self.coord_prefill = int(coord_prefill+.5)
self.threshold = float(threshold)
self.lambda_coord = float(lambda_coord)
self.lambda_noobj = float(lambda_noobj)
self.lambda_obj = float(lambda_obj)
self.lambda_cls = float(lambda_cls)
self.mse = torch.nn.SmoothL1Loss(reduction='sum')
self.cel = torch.nn.CrossEntropyLoss(reduction='sum')
def forward(self, x, y):
nT = y.shape[1]
nA = self.anchors.shape[0]
#nB, _, nH, nW, _ = x.shape #geändert für yolo=True
nB, _, nH, nW = x.shape #original für yolo=False
nPixels = nH * nW
nAnchors = nA * nPixels
y = y.to(dtype=x.dtype, device=x.device)
x = x.view(nB, nA, -1, nH, nW).permute(0, 1, 3, 4, 2)
nC = x.shape[-1] - 5
self.seen += nB
anchors = self.anchors.to(dtype=x.dtype, device=x.device)
coord_mask = torch.zeros(nB, nA, nH, nW, 1, requires_grad=False, dtype=x.dtype, device=x.device)
conf_mask = torch.ones(nB, nA, nH, nW, requires_grad=False, dtype=x.dtype, device=x.device) * self.lambda_noobj
cls_mask = torch.zeros(nB, nA, nH, nW, requires_grad=False, dtype=torch.bool, device=x.device)
tcoord = torch.zeros(nB, nA, nH, nW, 4, requires_grad=False, dtype=x.dtype, device=x.device)
tconf = torch.zeros(nB, nA, nH, nW, requires_grad=False, dtype=x.dtype, device=x.device)
tcls = torch.zeros(nB, nA, nH, nW, requires_grad=False, dtype=x.dtype, device=x.device)
coord = torch.cat([
x[:, :, :, :, 0:1].sigmoid(), # X center
x[:, :, :, :, 1:2].sigmoid(), # Y center
x[:, :, :, :, 2:3], # Width
x[:, :, :, :, 3:4], # Height
], -1)
range_y, range_x = torch.meshgrid(
torch.arange(nH, dtype=x.dtype, device=x.device),
torch.arange(nW, dtype=x.dtype, device=x.device),
)
anchor_x, anchor_y = anchors[:, 0], anchors[:, 1]
x = torch.cat([
(x[:, :, :, :, 0:1].sigmoid() + range_x[None,None,:,:,None]), # X center
(x[:, :, :, :, 1:2].sigmoid() + range_y[None,None,:,:,None]), # Y center
(x[:, :, :, :, 2:3].exp() * anchor_x[None,:,None,None,None]), # Width
(x[:, :, :, :, 3:4].exp() * anchor_y[None,:,None,None,None]), # Height
x[:, :, :, :, 4:5].sigmoid(), # confidence
x[:, :, :, :, 5:], # classes (NOTE: no softmax here bc CEL is used later, which works on logits)
], -1)
conf = x[..., 4]
cls = x[..., 5:].reshape(-1, nC)
x = x[..., :4].detach() # gradients are tracked in coord -> not here anymore.
if self.seen < self.coord_prefill:
coord_mask.fill_(np.sqrt(.01 / self.lambda_coord))
tcoord[..., 0].fill_(0.5)
tcoord[..., 1].fill_(0.5)
for b in range(nB):
gt = y[b][(y[b, :, -1] >= 0)[:, None].expand_as(y[b])].view(-1, 6)[:,:4]
gt[:, ::2] *= nW
gt[:, 1::2] *= nH
if gt.numel() == 0: # no ground truth for this image
continue
# Set confidence mask of matching detections to 0
iou_gt_pred = iou(gt, x[b:(b+1)].view(-1, 4))
mask = (iou_gt_pred > self.threshold).sum(0) >= 1
conf_mask[b][mask.view_as(conf_mask[b])] = 0
# Find best anchor for each gt
iou_gt_anchors = iou_wh(gt[:,2:], anchors)
_, best_anchors = iou_gt_anchors.max(1)
# Set masks and target values for each gt
nGT = gt.shape[0]
gi = gt[:, 0].clamp(0, nW-1).long()
gj = gt[:, 1].clamp(0, nH-1).long()
conf_mask[b, best_anchors, gj, gi] = self.lambda_obj
tconf[b, best_anchors, gj, gi] = iou_gt_pred.view(nGT, nA, nH, nW)[torch.arange(nGT), best_anchors, gj, gi]
coord_mask[b, best_anchors, gj, gi, :] = (2 - (gt[:, 2] * gt[:, 3]) / nPixels)[..., None]
tcoord[b, best_anchors, gj, gi, 0] = gt[:, 0] - gi.float()
tcoord[b, best_anchors, gj, gi, 1] = gt[:, 1] - gj.float()
tcoord[b, best_anchors, gj, gi, 2] = (gt[:, 2] / anchors[best_anchors, 0]).log()
tcoord[b, best_anchors, gj, gi, 3] = (gt[:, 3] / anchors[best_anchors, 1]).log()
cls_mask[b, best_anchors, gj, gi] = 1
tcls[b, best_anchors, gj, gi] = y[b, torch.arange(nGT), -1]
coord_mask = coord_mask.sqrt()
conf_mask = conf_mask.sqrt()
tcls = tcls[cls_mask].view(-1).long()
cls_mask = cls_mask.view(-1, 1).expand(nB*nA*nH*nW, nC)
cls = cls[cls_mask].view(-1, nC)
loss_coord = self.lambda_coord * self.mse(coord*coord_mask, tcoord*coord_mask) / (2 * nB)
loss_conf = self.mse(conf*conf_mask, tconf*conf_mask) / (2 * nB)
loss_cls = self.lambda_cls * self.cel(cls, tcls) / nB
#print(loss_coord, ", ", loss_conf, ", ", loss_cls)
return loss_coord + loss_conf + loss_cls
network.train()
loss_train_epoch=[]
loss_val_epoch=[]
for e in range(num_epochs):
print("epoch_nr: ", f'{e+1}')
loss_val_batch=[]
with torch.no_grad():
xv=len(input_img_v)
for bv_idx in range(xv):
input_v=input_img_v[bv_idx]
out_v=network(input_v,yolo=False)
pred_v=out_v
target_v=target_bbx_v[bv_idx]
loss_v=lossfunc(pred_v,target_v)
loss_val_batch.append(loss_v.item())
loss_val_epoch.append(sum(loss_val_batch)/len(loss_val_batch))
print("val loss: ",loss_val_epoch[len(loss_val_epoch)-1])
loss_train_batch=[]
x=len(input_img)
for b_idx in range(x):
optimizer.zero_grad()
input=input_img[b_idx]
out2 = network(input, yolo=False)
pred2=out2
target=target_bbx[b_idx]
loss = lossfunc(pred2, target)
loss.backward()
loss_train_batch.append(loss.item())
optimizer.step()
loss_train_epoch.append(sum(loss_train_batch)/len(loss_train_batch))
print("train loss: ",loss_train_epoch[len(loss_train_epoch)-1])
network.eval()
Thanks for your help ![]()