Hello guys I try to use inception block for my task in deep learning. I find the pytorch implementation in here which implement paper from here . However I found strange in the InceptionA which should be using 3X3 filter not 5X5 . But I am not sure maybe I wrong. The detail can be seen In my image, I have pointed the problem described in the image that I upload. So should I cange to 3X3 or 5X5?
-Thank you-
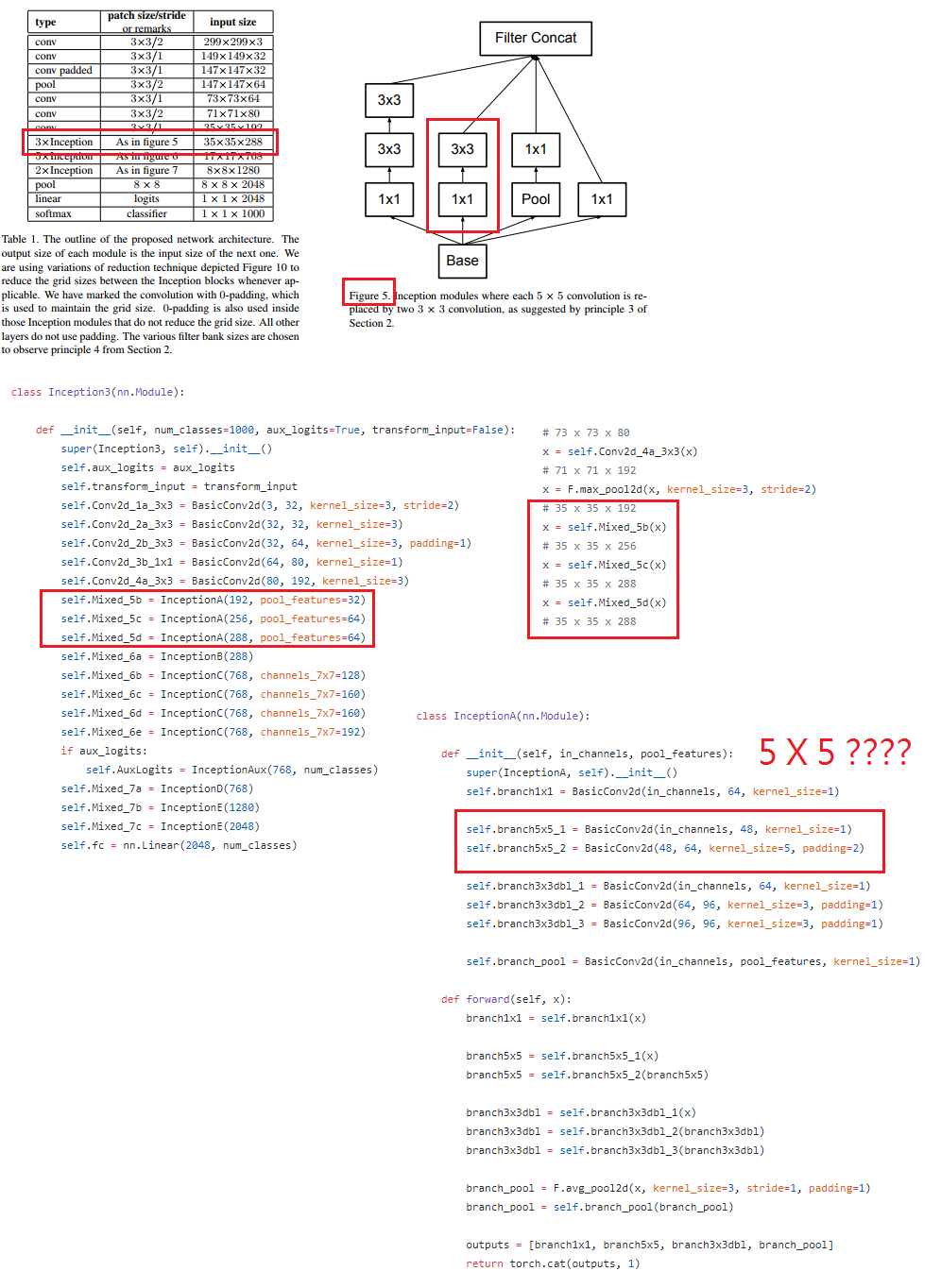
What you are seeing is what is implemented in Figure 4 of the same paper: “The original inception block”
@smth However there are multiple 3X3 Convolution. If we see figure 4 and use 5X5 the 3X3 convolution should be 1 times. However in implementation is using multiple 3X3 convolution, so I just think that 5X5 should bechange into 3X3.
I just think the code should be like here.
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
change with this
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=3, padding=1)
Am I right?, sorry I just learn about this and not have so much knowledge about it.
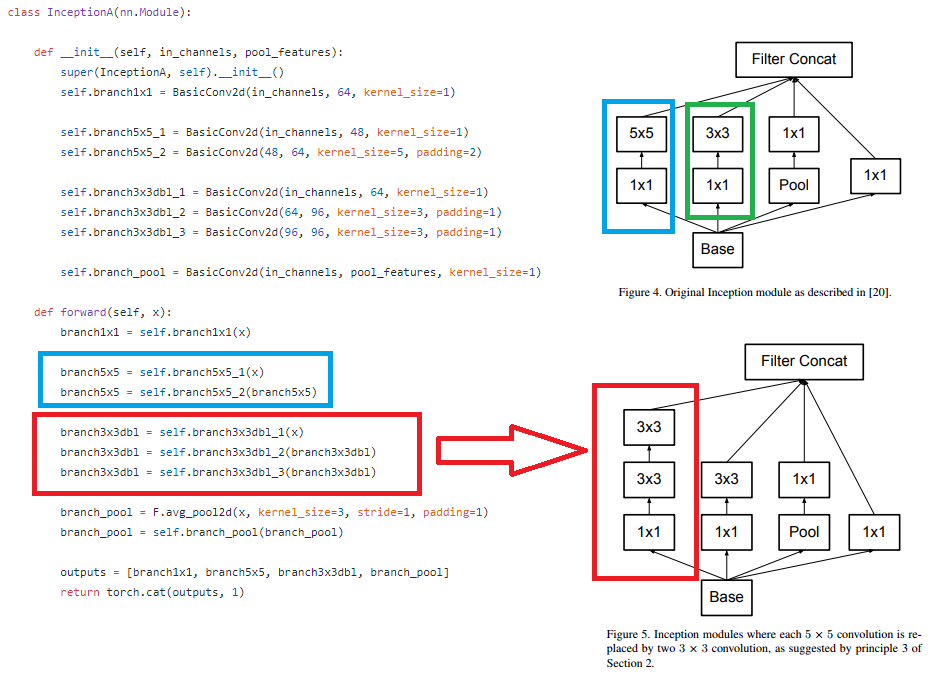
@smth However there are multiple 3X3 Convolution. If we see figure 4 and use 5X5 the 3X3 convolution should be 1 times. However in implementation is using multiple 3X3 convolution, so I just think that 5X5 should bechange into 3X3.
I just think the code should be like here.
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
change with this
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=3, padding=1)
Am I right?, sorry I just learn about this and not have so much knowledge about it.
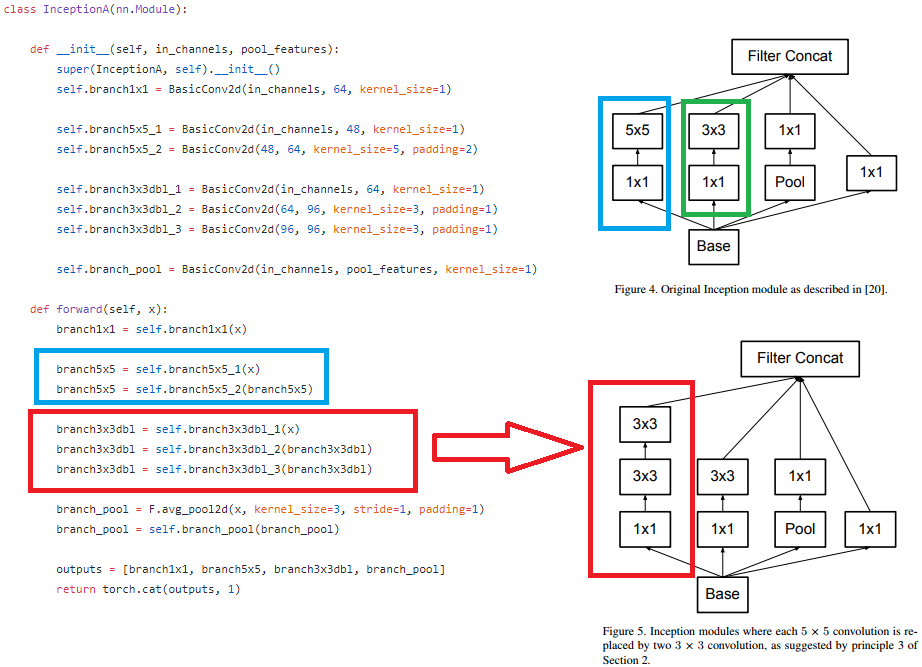
I’m still unsure why the inception module takes some parts from Figure 4 and some from Figure 5 in the paper. From the code it looks like the InceptionA module has a 5x5 branch as per Figure 4 (inception v1 / googlenet) but the 3x3 branch is as per Figure 5.
I also found some other discrepancies like the fact that inception_v3 architecture as per Table 1 in the paper uses a conv with 3x3 / stride=1 / input = 73x73x64 right after 1st pool. However in the code, Conv2d_3b_1x1 after 1st pool uses 1x1 not 3x3.
Could someone please explain the idea behind these choices? I’m assuming this inception_v3 has to match with Google’s implementation since the pretrained weights were directly converted from Google. In that case how do we explain the differences between Google’s implementation and the arch reported on their paper?
cc: @smth
the arch reported in the paper is slightly off from the weights they released. we followed the released weights.
That makes sense. Thanks @smth!