Hello, I cannot get my neural network to give the same accuracy and loss results between runs from different jobs, even though I manually set the seed.
Specifically, while different runs in the same job result in the same accuracies and losses, runs with the same parameters and same set seed sent through different jobs result in very different accuracies and losses.
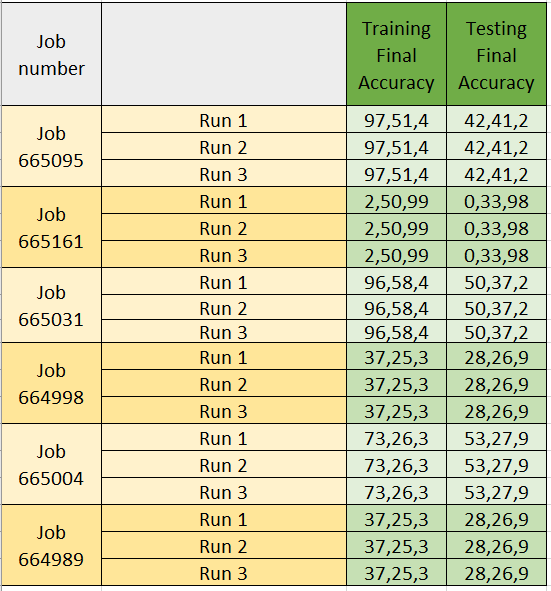
My understanding is that with the seed set manually, different runs and different jobs should give the same results. Therefore, advice on why I find such different results between runs from different jobs (and not between runs from the same job) would be highly appreciated.
Also, the difference in the results are too high to be only due to randomness. I thought this could be to some issues in the initialization but I am just combining standard layers, which to my understanding are initialised with meaningful values.
Please find below the code for your reference.
```
for run_counter in range(num_run):
clean_and_check_memory()
manualSeed = 4
t.manual_seed(manualSeed)
numpy.random.seed(manualSeed)
random.seed(manualSeed)
if (device != 'cpu'):
t.cuda.manual_seed(manualSeed)
t.cuda.manual_seed_all(manualSeed)
t.backends.cudnn.enabled = False
t.backends.cudnn.benchmark = False
t.backends.cudnn.deterministic = True
# CREATE TRAINDATASET & TRAINLOADER:
csvfileTrain = open(csvfileTrain_name)
if run_counter == 0:
suffix += "csvfileTrain_" + os.path.basename(csvfileTrain_name) + "_"
path_to_jsonTrain = os.path.join(path_to_jsonTrain, '*.json')
datasetTrain = ActionsDataset(csvfileTrain, path_to_jsonTrain)
dataloaderTrain = DataLoader(dataset=datasetTrain, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
# CREATE EVALDATASET & EVALLOADER:
csvfileEval = open(csvfileEval_name)
path_to_jsonEval = os.path.join(path_to_jsonEval, '*.json')
datasetEval = ActionsDataset(csvfileEval, path_to_jsonEval)
dataloaderEval = DataLoader(dataset=datasetEval, batch_size=4 * BATCH_SIZE, shuffle=False, num_workers=0)
# CREATE TESTDATASET & TESTLOADER:
csvfileTest = open(csvfileTest_name)
path_to_jsonTest = os.path.join(path_to_jsonTest, '*.json')
datasetTest = ActionsDataset(csvfileTest, path_to_jsonTest)
dataloaderTest = DataLoader(dataset=datasetTest, batch_size=4 * BATCH_SIZE, shuffle=False, num_workers=0)
l1_fact = l1_fact_set[hyp_par_exp_i_l1]
l2_fact = l2_fact_set[hyp_par_exp_i_l2]
model = MultiHead.PrednetResNet(4, 121, 9, 121, 121,
compute_head1=head1_on, computehead2=head2_on, computehead3=head3_on)
model = model.to(device)
criterion_h1 = t.nn.CrossEntropyLoss(reduction=reduction_CSE)
criterion_h2= t.nn.KLDivLoss(reduction=reduction_KlDiv)
optimizer = t.optim.Adam(model.parameters(), lr=lr, weight_decay=l2_fact)
def epoch_exc(ep_train=False, ep_test=False, ep_eval=False, dataloader=None, modelused=None, pre_title=''):
if ep_train:
epochtitle = 'Training'
elif ep_test:
epochtitle = 'Testing'
else:
epochtitle = 'Valid'
h1_correct = 0
h1_total = 0
h2_total = 0
loss = 0
loss_total = 0
epochs_time = 0
if ep_train:
t.set_grad_enabled(True) # only if training, use gradients
model.train()
else:
t.set_grad_enabled(False)
# START BATCH ITERATION:
for i, data in enumerate(dataloader):