I trained a VAE on a dataset of 64*64 grayscale images. My embedding size is 256. If I save my embedded dataset as a tsv file, and upload it on https://projector.tensorflow.org/, I get a usable embedding:
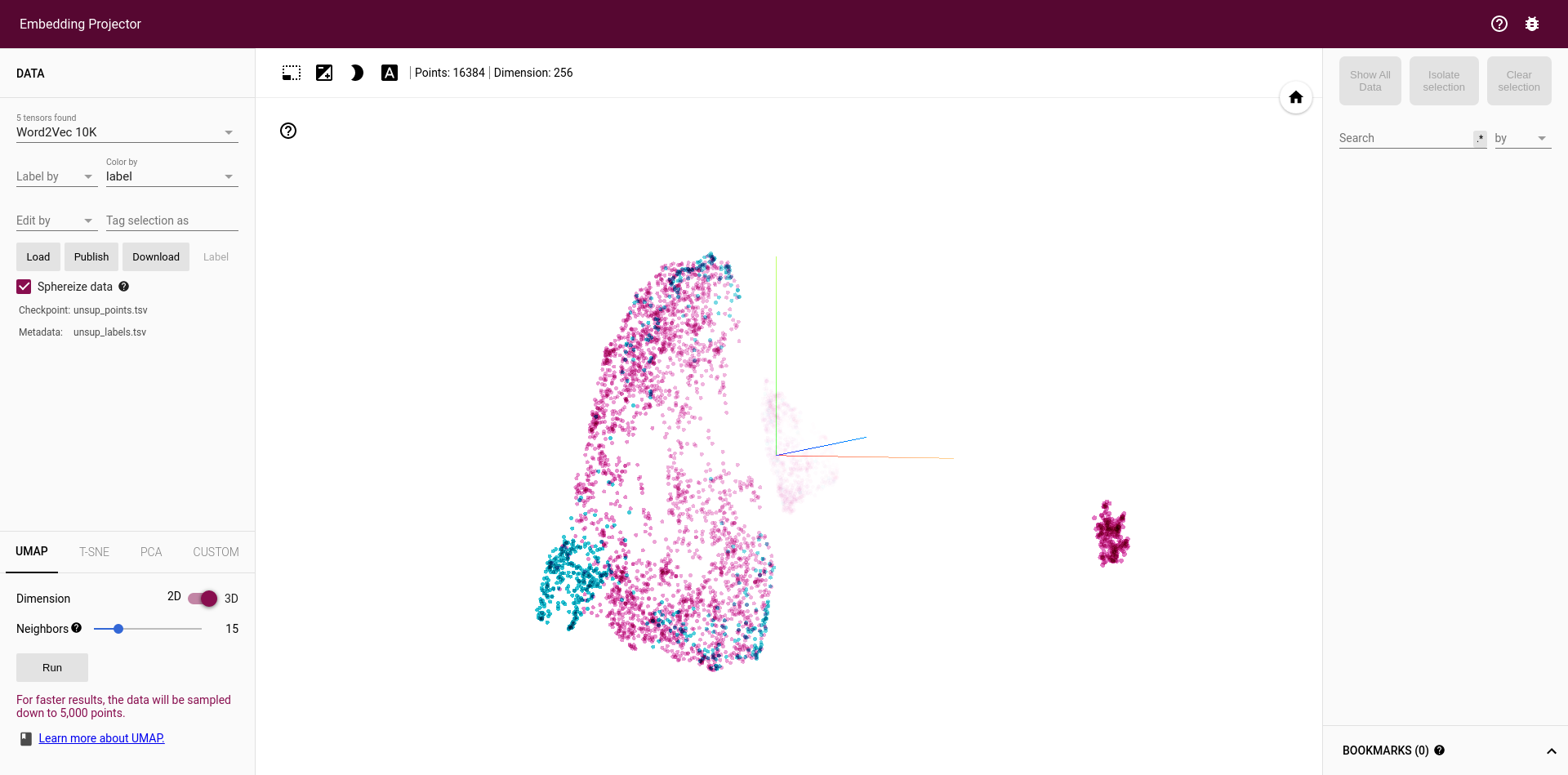
I would like to add image labels, for visualization purposes. To do this, I need to use the SummaryWriter class. As a test, I’m passing the exact same tsv file to the summary writer:
vae_unsup_points = np.loadtxt(os.path.join(root_path, "vae_unsup_points.tsv"))
vae_unsup_labels = np.loadtxt(os.path.join(root_path, "vae_unsup_labels.tsv"))
writer_VAE = SummaryWriter("/path/to/logdir/VAE")
writer_VAE.add_embedding(vae_unsup_points, metadata=vae_unsup_labels)
writer_VAE.close()
It produces completely different (and unusable) results. I think there is too much variation for it to be related to the randomness in UMAP’s initialization:
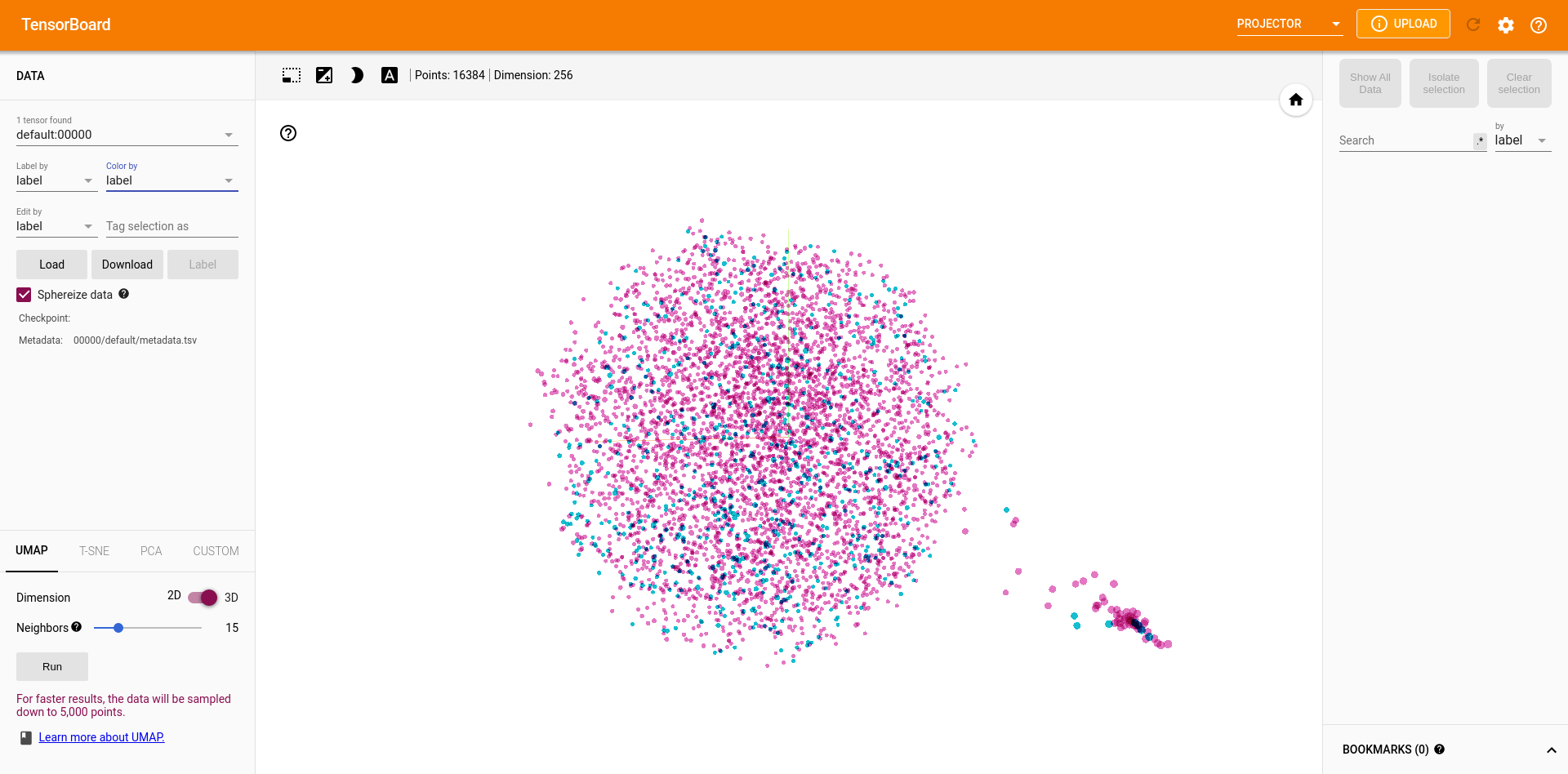
I am very confused by this result, has anybody ever encountered this issue before ?