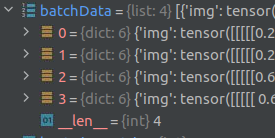
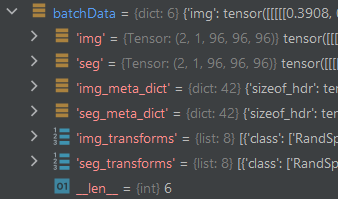
Hi CacheDataset is provided by MONAI framework (Data — MONAI 1.1.0 Documentation) and I also attached output of debugger …as you can see wrong shape is list of dicts. I also added expected shape. THanks
Maybe a custom collate_fn could help as I don’t know why the original code doesn’t work.
My code snippet shows that dicts are acceptable and won’t create the mentioned output.
Isn’t it because the batch contains elements that are not tensors (dicts and list) that pytorch unable to batch? in your last code snippet you are returning a dict but its values are tensors so it is clear how to batch across samples. As I understand the question we will have:
def __getitem__(self, index):
x = img, img_meta_dict, img_transforms # tensor, dict, list
y = seg, seg_meta_dict, seg_transforms # tensor, dict, list
return {"img": x, "target": y}
@David_Hresko I think you can change the get_item for something as follow:
def __getitem__(self, index):
img_transforms = Compose(img_transforms)
x = img_transforms(img)
seg_transforms = Compose(seg_transforms)
y = seg_transforms(img)
return {"img": x, "target": y, "img_meta": img_meta_dict, "seg_meta": seg_meta_dict}
and:
for (imgs, targets, imgs_meta, targets_meta) in train_loader:
your_code
then the imgs and targets will have the expected shapes