Hi,
I am training a 3d object detection network and I realize that the magnitudes of the gradients are increasing at the lower layers (input layers) of the networks. I use a Resnet50 network as a backbone, a FPN and then custom heads. I use BN in all layers of the network. The network has two input modalities, depth and rgb, which I ingest via two resnet-stems.
The mean and std of the activations are shown in the graph below: (the means on the left graph, the stds on the right graph).
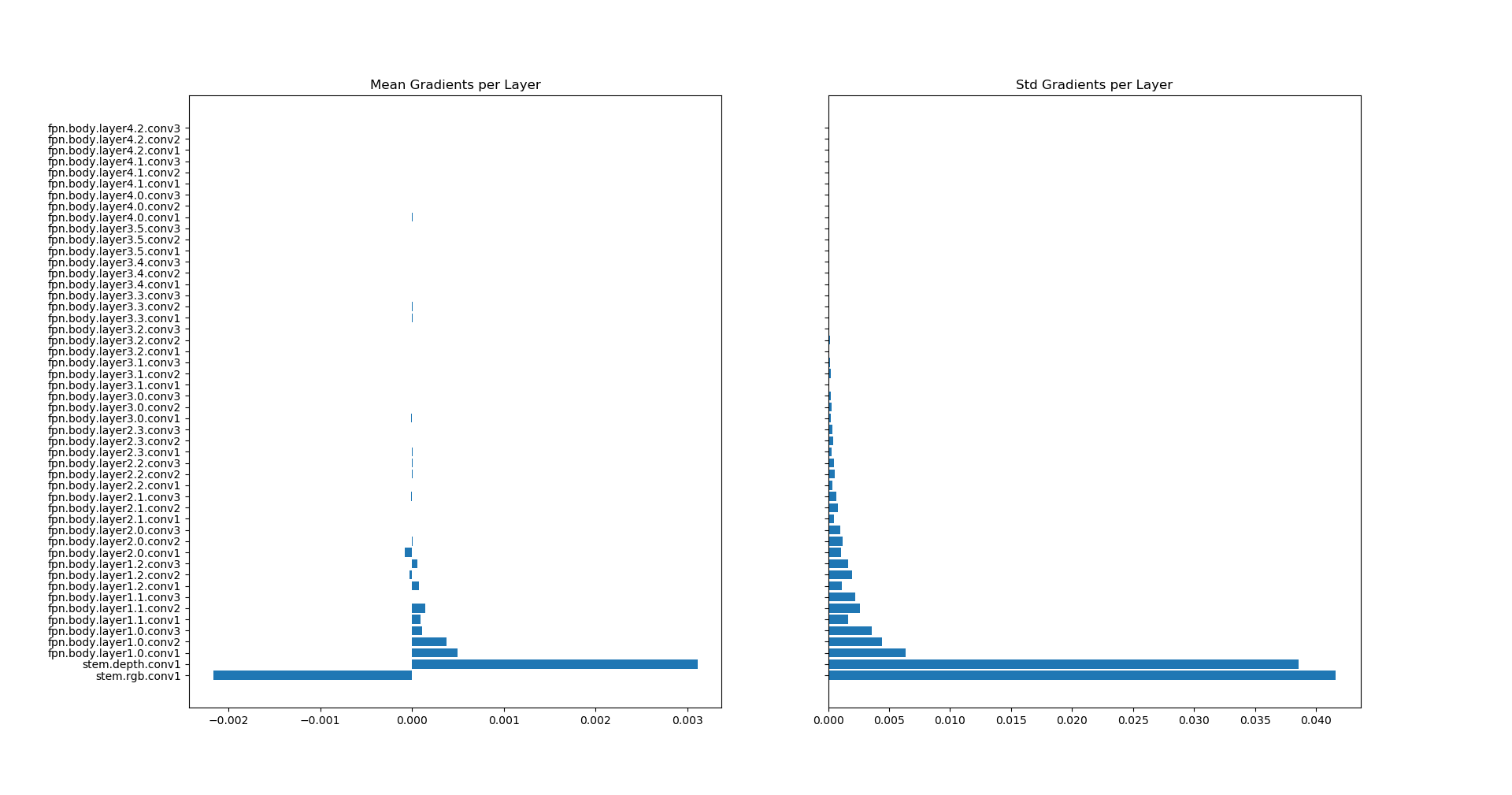
As can be seen, the gradients in the higher layers (towards the end of the network) have a comparatively low stds and mean, while the lower layers have a high std and (absolute) mean.
Does somebody know how I could have a more balanced gradient distribution? Would that even be desirable? I am using the default activations of pytorch.