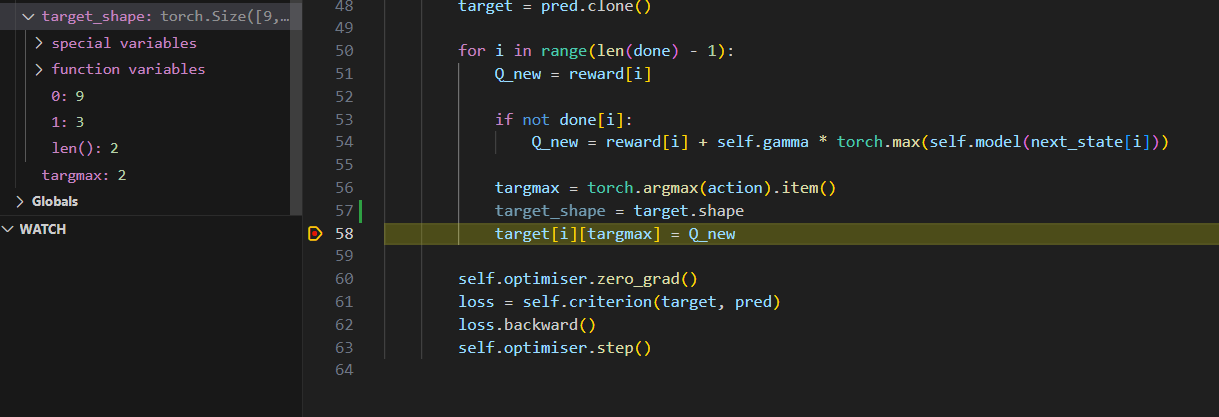
Hi, I’ve been encountering this issue for the past day and have been unsure as to how to fix it. The index which is out of bounds isn’t consistent either.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import os
class Linear_QNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.linear2(x)
return x
def save(self, file_name='model.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.makedirs(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
class QTrainer:
def __init__(self, model, lr, gamma):
self.lr = lr
self.gamma = gamma
self.model = model
self.optimiser = optim.Adam(model.parameters(), lr=self.lr)
self.criterion = nn.MSELoss() # Loss function
def train_step(self, state, action, reward, next_state, done):
state = torch.tensor(state, dtype=torch.float)
next_state = torch.tensor(next_state, dtype=torch.float)
action = torch.tensor(action, dtype=torch.long)
reward = torch.tensor(reward, dtype=torch.float)
if len(state.shape) == 1:
state = torch.unsqueeze(state, 0)
next_state = torch.unsqueeze(next_state, 0)
action = torch.unsqueeze(action, 0)
reward = torch.unsqueeze(reward, 0)
done = (done, )
pred = self.model(state)
target = pred.clone()
for i in range(len(done) - 1):
Q_new = reward[i]
if not done[i]:
Q_new = reward[i] + self.gamma * torch.max(self.model(next_state[i]))
targmax = torch.argmax(action).item()
target[i][targmax] = Q_new
self.optimiser.zero_grad()
loss = self.criterion(target, pred)
loss.backward()
self.optimiser.step()
target[i][targmax] = Q_new is the line which has the issue