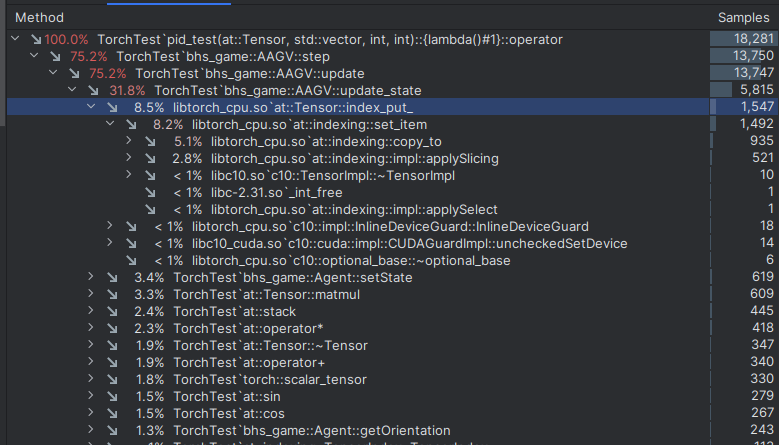
I am trying to understand why my code is 3x slower on GPU. I’m profiling and debugging my update state function, which should be straightforward.
Everything should be on the GPU, so I do not understand why placing these values would take so long. However, when looking at the profiling, we can see that the index_put_ is running from libtorch_cpu.so, which indicates that most of the function is actually performed on the CPU, even though all the values are on the GPU.
I’m new to using torch in c++, so please help me understand.
void AAGV::update_state(double dt) {
auto deltaTime = torch::scalar_tensor(dt, TOptions(torch::kDouble, device));
torch::Tensor orientation = getOrientation();
// TODO:: Very slow on gpu, OPTIMIZE THIS
_B.index_put_({0, 0}, torch::cos(orientation) * deltaTime);
_B.index_put_({1, 0}, torch::sin(orientation) * deltaTime);
_B.index_put_({2, 1}, deltaTime);
// torch::Tensor B = torch::tensor({{torch::cos(orientation) * deltaTime, 0.},
// {torch::sin(orientation) * deltaTime, 0.},
// {0., deltaTime}},
// TOptions(torch::kDouble, device));
// double data[] = {torch::cos(orientation).*dt, 0., torch::sin(orientation) * dt, 0., 0., dt};
// torch::Tensor B = torch::from_blob(data, {3, 2}, torch::kDouble).to(device);
torch::Tensor vel = torch::stack({getLinearVelocity(), getAngularVelocity()});
torch::Tensor new_state = A.matmul(getState()) + _B.matmul(vel);
setState(new_state);
}