Hello Folks, Any help would be appreciated. I am stuck at one point.
I am trying to use the siamese neural network for my images to predict, Images are similar or not. I am getting the following error while loading data into the dataloader. why the data loader is unable to load all images and it is giving me an error can not choose from the empty sequence.
Causing an error at:
for i, data in enumerate(trainloader,0):
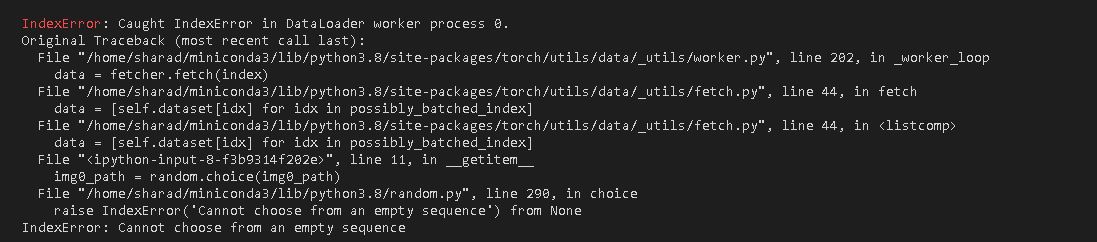
below is my whole code:
BATCH_SIZE=64
NUMBER_EPOCHS=100
IMG_SIZE=100
#F09xx are used for validation.
val_famillies = "XZY"
#An example of data:"../input/train/F00002/MID1/P0001_face1.jpg"
all_images = glob("/home/Phillip/Data/test3/*/*.png")
print(len(all_images))
#train_images = [x for x in all_images if val_famillies not in x]
#val_images = [x for x in all_images if val_famillies in x]
train_images = all_images[0:2000]
print(len(train_images))
val_images = all_images[2000:]
print(len(val_images))
train_person_to_images_map = defaultdict(list)#Put the link of each picture under the key word of a person such as "F0002/MID1"
for x in train_images:
train_person_to_images_map[x.split("/")[-3] + "/" + x.split("/")[-2]].append(x)
val_person_to_images_map = defaultdict(list)
for x in val_images:
val_person_to_images_map[x.split("/")[-3] + "/" + x.split("/")[-2]].append(x)
ppl = [x.split("/")[-3] + "/" + x.split("/")[-2] for x in all_images]
relationships = pd.read_csv("/home/phillip/Data/Test.csv")
#print(relationships)
relationships = list(zip(relationships.p1.values, relationships.p2.values))#For a List like[p1 p2], zip can return a result like [(p1[0],p2[0]),(p1[1],p2[1]),...]
#print(relationships)
#relationships = [x for x in relationships if x[0] not in ppl and x[1] not in ppl]#filter unused relationships
print(len(relationships))
#train = [x for x in relationships if val_famillies not in x[0]]
#val = [x for x in relationships if val_famillies in x[0]]
train = relationships[0:9400]
val = relationships[9400:]
print("Total train pairs:", len(train))
print("Total val pairs:", len(val))
class trainingDataset(Dataset):#Get two images and whether they are related.
def __init__(self,imageFolderDataset, relationships, transform=None):
self.imageFolderDataset = imageFolderDataset
self.relationships = relationships #choose either train or val dataset to use
self.transform = transform
def __getitem__(self,index):
img0_info = self.relationships[index][0]#for each relationship in train_relationships.csv, the first img comes from first row, and the second is either specially choosed related person or randomly choosed non-related person
img0_path = glob("/home/phillip/Data/test3/"+img0_info+"/*.png")
img0_path = random.choice(img0_path)
cand_relationships = [x for x in self.relationships if x[0]==img0_info or x[1]==img0_info]#found all candidates related to person in img0
if cand_relationships==[]:#in case no relationship is mensioned. But it is useless here because I choose the first person line by line.
should_get_same_class = 0
else:
should_get_same_class = random.randint(0,1)
if should_get_same_class==1:#1 means related, and 0 means non-related.
img1_info = random.choice(cand_relationships)#choose the second person from related relationships
if img1_info[0]!=img0_info:
img1_info=img1_info[0]
else:
img1_info=img1_info[1]
img1_path = glob("/home/phillip/Data/test3/"+img1_info+"/*.png")#randomly choose a img of this person
img1_path = random.choice(img1_path)
else:#0 means non-related
randChoose = True#in case the chosen person is related to first person
while randChoose:
img1_path = random.choice(self.imageFolderDataset.imgs)[0]
img1_info = img1_path.split("/")[-3] + "/" + img1_path.split("/")[-2]
randChoose = False
for x in cand_relationships:#if so, randomly choose another person
if x[0]==img1_info or x[1]==img1_info:
randChoose = True
break
img0 = Image.open(img0_path)
img1 = Image.open(img1_path)
if self.transform is not None:#I think the transform is essential if you want to use GPU, because you have to trans data to tensor first.
img0 = self.transform(img0)
img1 = self.transform(img1)
return img0, img1 , should_get_same_class #the returned data from dataloader is img=[batch_size,channels,width,length], should_get_same_class=[batch_size,label]
def __len__(self):
return len(self.relationships)#essential for choose the num of data in one epoch
folder_dataset = dset.ImageFolder(root='/home/phillip/Data/test3')
trainset = trainingDataset(imageFolderDataset=folder_dataset,
relationships=train,
transform=transforms.Compose([transforms.Resize((IMG_SIZE,IMG_SIZE)),
transforms.ToTensor()
]))
trainloader = DataLoader(trainset,
shuffle=True,#whether randomly shuffle data in each epoch, but cannot let data in one batch in order.
num_workers=8,
batch_size=BATCH_SIZE)
valset = trainingDataset(imageFolderDataset=folder_dataset,
relationships=val,
transform=transforms.Compose([transforms.Resize((IMG_SIZE,IMG_SIZE)),
transforms.ToTensor()
]))
valloader = DataLoader(valset,
shuffle=True,
num_workers=8,
batch_size=BATCH_SIZE)
class SiameseNetwork(nn.Module):# A simple implementation of siamese network, ResNet50 is used, and then connected by three fc layer.
def __init__(self):
super(SiameseNetwork, self).__init__()
#self.cnn1 = models.resnet50(pretrained=True)#resnet50 doesn't work, might because pretrained model recognize all faces as the same.
self.cnn1 = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(3, 64, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(64),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(64, 64, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(64),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(64, 32, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(32),
nn.Dropout2d(p=.2),
)
self.fc1 = nn.Linear(2*32*100*100, 500)
#self.fc1 = nn.Linear(2*1000, 500)
self.fc2 = nn.Linear(500, 500)
self.fc3 = nn.Linear(500, 2)
def forward(self, input1, input2):#did not know how to let two resnet share the same param.
output1 = self.cnn1(input1)
output1 = output1.view(output1.size()[0], -1)#make it suitable for fc layer.
output2 = self.cnn1(input2)
output2 = output2.view(output2.size()[0], -1)
output = torch.cat((output1, output2),1)
output = F.relu(self.fc1(output))
output = F.relu(self.fc2(output))
output = self.fc3(output)
return output
import random
net = SiameseNetwork().cuda()
criterion = nn.CrossEntropyLoss() # use a Classification Cross-Entropy loss
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
counter = []
loss_history = []
iteration_number= 0
for epoch in range(0,NUMBER_EPOCHS):
print("Epoch:", epoch, " start.")
for i, data in enumerate(trainloader,0):
img0, img1 , labels = data #img=tensor[batch_size,channels,width,length], label=tensor[batch_size,label]
img0, img1 , labels = img0.cuda(), img1.cuda() , labels.cuda()#move to GPU
#print("epoch:", epoch, "No." , i, "th inputs", img0.data.size(), "labels", labels.data.size())
optimizer.zero_grad()#clear the calculated grad in previous batch
outputs = net(img0,img1)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
if i %10 == 0 :#show changes of loss value after each 10 batches
#print("Epoch number {}\n Current loss {}\n".format(epoch,loss.item()))
iteration_number +=10
counter.append(iteration_number)
loss_history.append(loss.item())
#test the network after finish each epoch, to have a brief training result.
correct_val = 0
total_val = 0
with torch.no_grad():#essential for testing!!!!
for data in valloader:
img0, img1 , labels = data
img0, img1 , labels = img0.cuda(), img1.cuda() , labels.cuda()
outputs = net(img0,img1)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).sum().item()
print('Accuracy of the network on the', total_val, 'val pairs in',val_famillies, ': %d %%' % (100 * correct_val / total_val))
show_plot(counter,loss_history)
My dataset folder structure is like this:
Dataset:
Class 1
Images
Class 2
Images
then why I am getting an error that cannot choose from empty sequences.??
