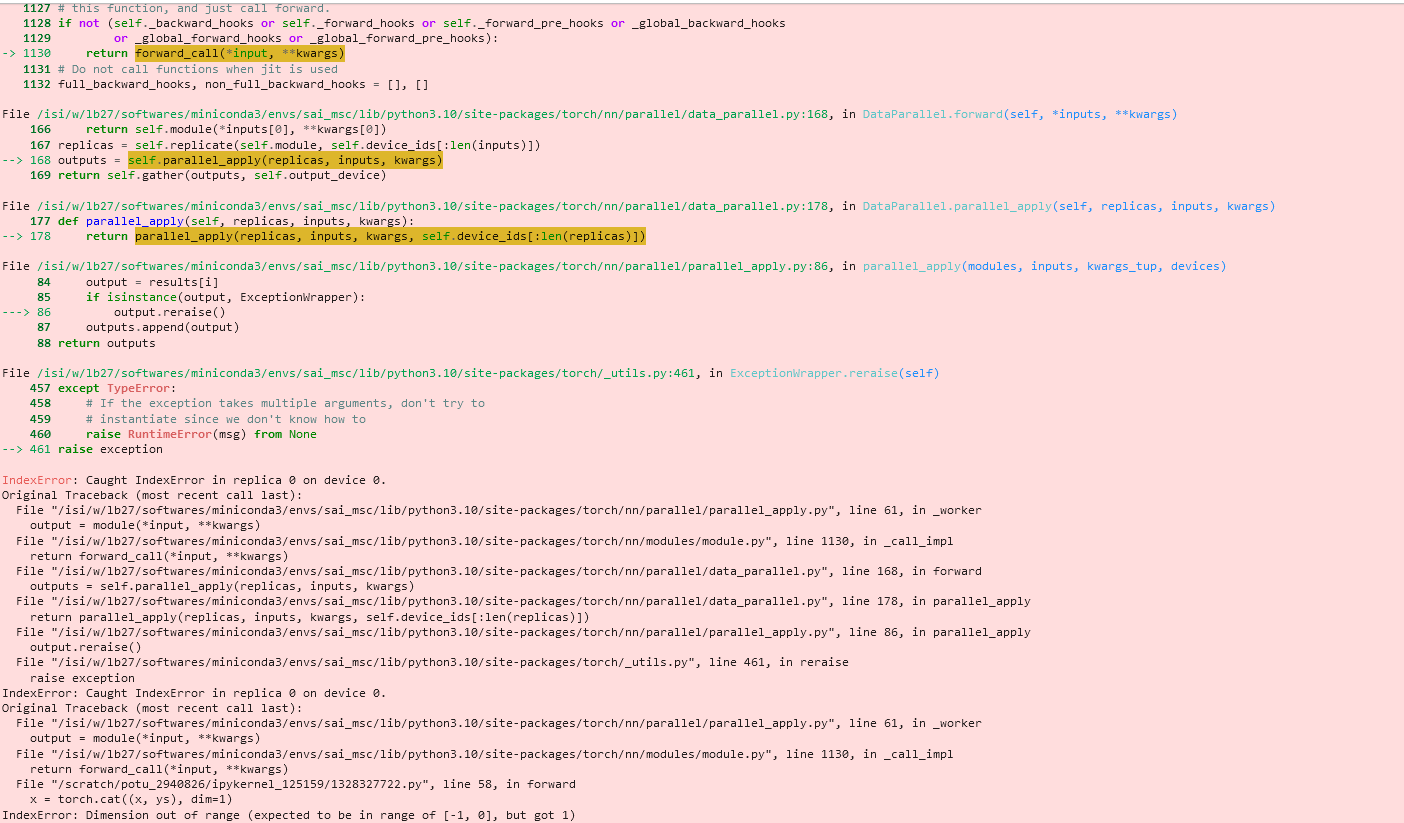
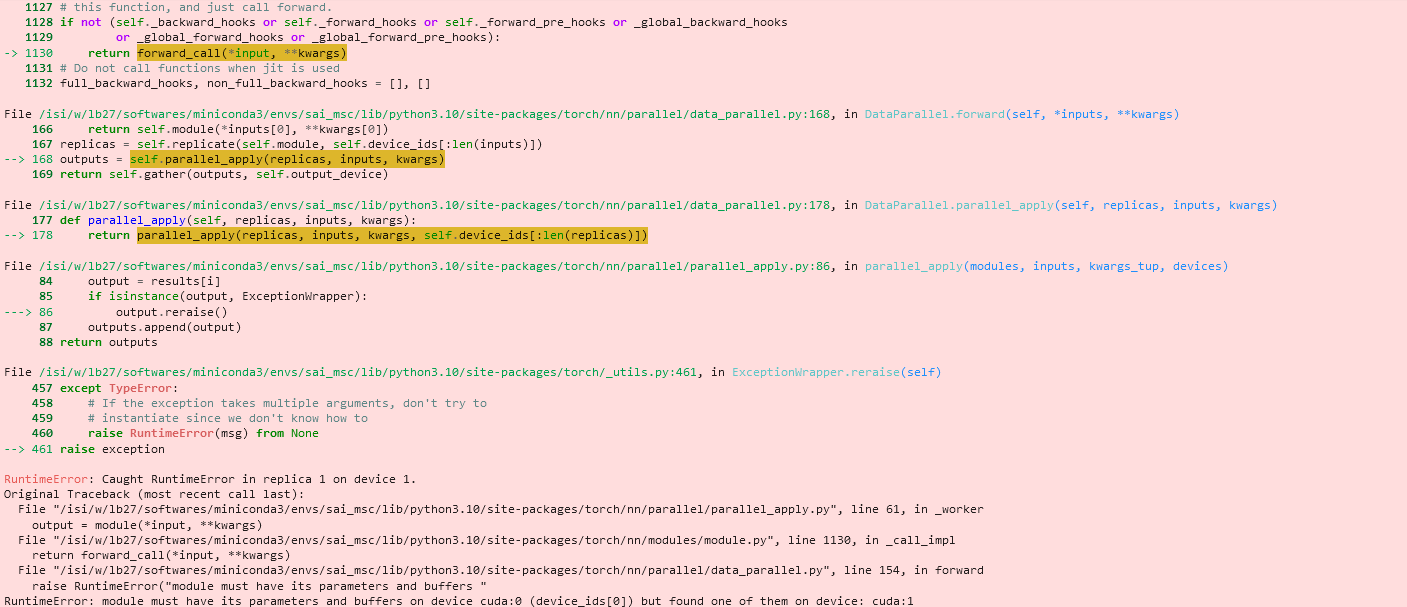
I using this GAN generator
import torch
import torch.nn as nn
class ResNet18_CIFAR10_Deconv_GAN(nn.Module):
def __init__(self, latent_dim=512,fw_layers=1,num_classes=3):
super( ResNet18_CIFAR10_Deconv_GAN, self).__init__()
self.latent_dim = latent_dim
self.num_classes = num_classes
# Define the layers
self.fc = nn.Linear(self.latent_dim, 1024 * 62 * 62) # output shape: [batch_size, 1024*62*62]
self.conv1 = nn.Sequential(
nn.ConvTranspose2d(1024, 512, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True) # output shape: [batch_size, 512, 124, 124]
)
self.conv2 = nn.Sequential(
nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True) # output shape: [batch_size, 256, 248, 248]
)
self.conv3 = nn.Sequential(
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True) # output shape: [batch_size, 128, 496, 496]
)
self.conv4 = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True) # output shape: [batch_size, 64, 992, 992]
)
self.conv5 = nn.Sequential(
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(True) # output shape: [batch_size, 32, 1984, 1984]
)
self.conv6 = nn.Sequential(
nn.ConvTranspose2d(32, 3, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(3),
nn.ReLU(True) # output shape: [batch_size, 3, 1994, 1994]
#nn.Tanh()
)
self.conv7 = nn.Sequential(
nn.ConvTranspose2d(3, 3, kernel_size=11, stride=1, padding=0),
nn.Tanh() # output shape: [batch_size, 3, 1994, 1994]
)
def forward(self, z,y_hat):
# Reshape the input noise vector to a 4D tensor
x = z
ys = F.one_hot(y_hat, num_classes=self.num_classes)
x = torch.cat((x, ys), dim=1)
x = self.fc(z)
x = x.view(-1, 1024, 62, 62) # reshape to [batch_size, 1024, 62, 62]
# Upscale the image with transposed convolutions
x = self.conv1(x) # output shape: [batch_size, 512, 124, 124]
x = self.conv2(x) # output shape: [batch_size, 256, 248, 248]
x = self.conv3(x) # output shape: [batch_size, 128, 496, 496]
x = self.conv4(x) # output shape: [batch_size, 64, 992, 992]
x = self.conv5(x) # output shape: [batch_size, 32, 1984, 1984]
x = self.conv6(x) # output shape: [batch_size, 3, 1994, 1994]
x = self.conv7(x)
return x
To use in
def learn_prototype(model, generator, optimizer_g, n_epochs, trainset, batch_size, min_val, max_val,
device, fw_layers=1, save_dir=None):
model.eval()
generator.train()
gan_dict = {"min": min_val, "max": max_val}
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
for e in range(n_epochs):
running_loss_gen = 0
# set requires grad False
set_requires_grad(model, False)
#set_requires_grad(classifier, False)
for i, (images, gt_images) in enumerate(trainloader):
images = images.to(device)
gt_images = gt_images.to(device)
# train generator
optimizer_g.zero_grad()
zs_real, ys_real = get_classifier_features(model, images)
print(zs_real.shape)
print(ys_real.shape)
#for l_idx in range(fw_layers):
zs_real[0] = (zs_real[0] - min_val) / (max_val - min_val)
zs_real = zs_real.to(device)
ys_real = ys_real.to(device)
x_hat = generator(zs_real, ys_real)
x_hat = x_hat + images
g_loss = torch.mean(ase_loss_weighted(x_hat, gt_images, device))
running_loss_gen += g_loss.item()
g_loss.backward()
optimizer_g.step()
running_loss_gen = running_loss_gen / len(trainset)
print('Epoch {} -- Reconstruction Loss: {:.2f}'.format(e, running_loss_gen))
if (e + 1) % 10 == 0:
mapping = {"generator": copy.deepcopy(generator.state_dict())}
gan_dict[e] = mapping
torch.save(gan_dict, save_dir)
return generator
using a dataparallel like
gen = nn.DataParallel(gen,device_ids = [0,1,3])
and calling the function as
learn_prototype(model = trained_model,
generator = gen,
optimizer_g = gen_optimizer,
n_epochs = 150,
trainset = dataset,
batch_size = 2,
min_val = norm_min,
max_val = norm_max,
device= device,
fw_layers=1,
save_dir="Models/generator_model/")
But I am getting this strange error. Can Someone help. I am not sure where am I doing wrong.