Hi,
I have problem with IndexError on evaluation model. I use transfer learning on VGG16 and I replaced last layer for nn.Linear(4096, 264), because I have 264 classes.
I got IndexError: index 43352 is out of bounds for dimension 0 with size 32218
My length of test_dataset is 32218.
Here is my code of splitting into train and test set:
train_size = int(0.8 * len(mvc_dataset))
test_size = len(mvc_dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(mvc_dataset, [train_size, test_size])
num_train = len(train_dataset)
indices = list(range(num_train))
split = int(np.floor(0.20 * num_train))
np.random.shuffle(indices)
train_idx, test_idx = indices[split:], indices[:split]
train_sampler = SubsetRandomSampler(train_idx)
test_sampler = SubsetRandomSampler(test_idx)
train_loader = nc.SafeDataLoader(train_dataset,
sampler=train_sampler, batch_size=1)
test_loader = nc.SafeDataLoader(test_dataset,
sampler=test_sampler, batch_size=1)
And when I got error:
for images, annotations in test_loader:
images = Variable(images.cuda() if torch.cuda.is_available() else images, requires_grad=True)
annotations = Variable(annotations.cuda() if torch.cuda.is_available() else annotations)
outputs = model(images)
_, predicted = torch.max(outputs)
total += annotations.size[0]
correct += (predicted == annotations).sum().item()
Any know, what should I do in this situation?
I think the problem comes from you using both the torch.utils.data.random_split and SubsetRandomSampler solutions.
The first one gives you two datasets, of (roughly) 80% and 20% of the size of the original dataset. Then you shuffle all the indices and split them (with quite possibly a different split than the first random_split), which you feed into the SubsetRandomSampler.
This doesn’t work, because you could have any index (from 0 to len(mvc_dataset) - 1) attributed to the test_sampler. However, since the test_sampler is only (roughly) 20% of the mvc_dataset, you get the error. This error probably gives you different indices each time (unless there’s a seed setup somewhere).
The solution would be using either of the two solutions. If you simply want to randomly split your dataset in train and test sets and shuffle them separately, use torch.utils.data.random_split and something like DataLoader(shuffle=True).
1 Like
Thanks, It’s works, but now I got error:
TypeError: iteration over a 0-d tensor
in line:
_, predicted = torch.max(outputs)
for images, annotations in val_loader:
images = Variable(images.cuda() if torch.cuda.is_available() else images, requires_grad=True)
annotations = Variable(annotations.cuda() if torch.cuda.is_available() else annotations)
outputs = model(images)
_, predicted = torch.max(outputs)
total += annotations.size[0]
correct += (predicted == annotations).sum().item()
Do I have add 1 after outputs for example: _, predicted = torch.max(outputs, 1)?
Indeed, if you want the predictions (argmax) as well, you need the dim parameter set. The actual value depends on the shape of your outputs tensor.
Ok, It’s all correct, but after this error I got last:
RuntimeError: The size of tensor a (64) must match the size of tensor b (264) at non-singleton dimension 1
I use pretrained VGG16 network as follow and my batch size is equal 64:
# Load pre-trained model, then cut off its last layer and freeze its weights
model = models.vgg16(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# Add custom fully-connected layer with 4096 neurons for the hidden layer
model.fc = nn.Linear(4096, 264).to(device)
What line throws the error? Could you paste a more complete stacktrace?
This line throw this error.
correct += (predicted == annotations).sum().item()
I also try without .item() and it does not work.
I’m guessing that the variables predicted and annotations don’t have the same shape. Could you print their respective shape, just before that line is called?
Also, I think comparing tensors this way does not work. Apparently, predicted.eq(annotations).sum().item() might be what you’re looking for.
1 Like
predicted = torch.Size([1])
annotations = torch.Size([1, 264])
I’m guessing you are working on multi-class single-label classification, with 264 classes but only one target per input, right?
In that case, you need to check if the prediction is the correct one, so check if your prediction is the same as the index in your one-hot target vector!
Something like that should work:
_, predicted = torch.max(outputs, 1)
_, target = torch.max(annotations, 1)
correct += predicted.eq(target).sum().item()
1 Like
Yeah! It’s working!!! Thanks!!! So what is now the best way to calculate the accuracy in this task?
1 Like
Good to know it works now 
I usually use something similar to this, which enables you to compute accuracy at different ranks (the topk argument, e.g. topk=(1, 3, 5) for ranks 1, 3 and 5):
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
This version was found here, I don’t know if this is the real original though.
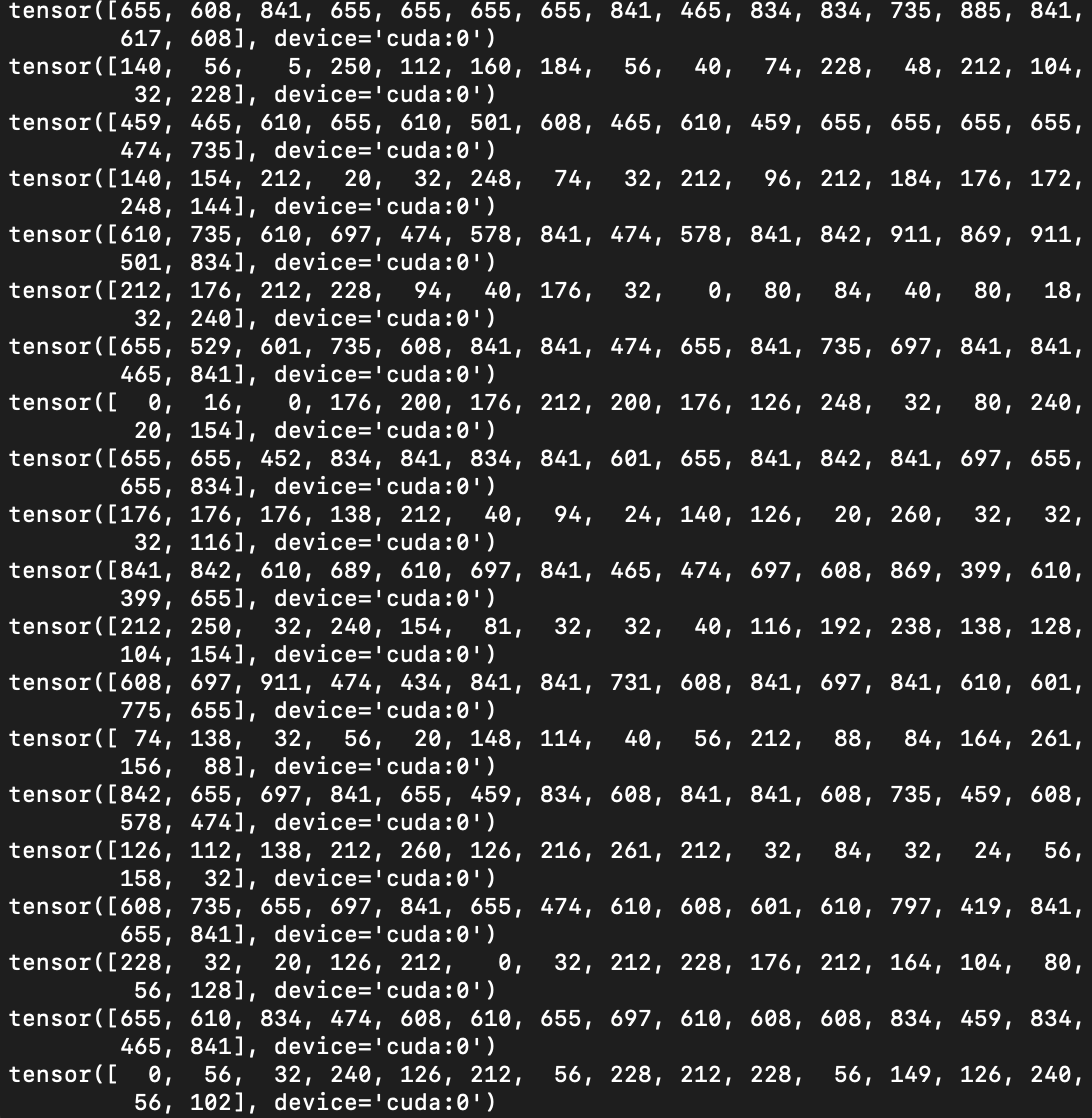
Now, my predicted values on first line, and target values on second, and so on…
If i printed correct value, I get 0. Why?
Seems like the model has not converged yet, keep training it and, if everything is setup correctly, it should slowly increase accuracy