When converting columns of csv files into torch token and label tensors, I got this error when attempting to run the AlbertForTokenClassification model on the token tensor.
Code:
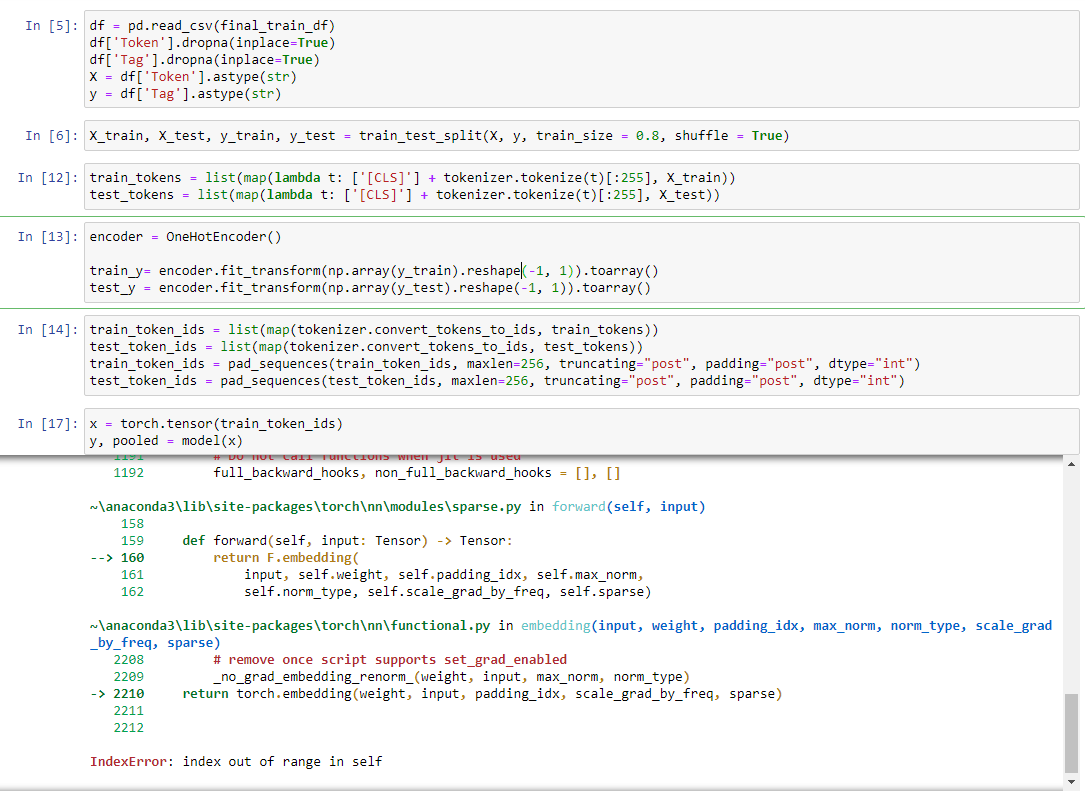
I tried rotating the input so it is [256, 34546] instead of [34536, 256], but that did not work, either. I ended up getting the error “RuntimeError: The expanded size of the tensor (34546) must match the existing size (256) at non-singleton dimension 1. Target sizes: [256, 34546]. Tensor sizes: [1, 256].”
Any help would be appreciated, thanks