Using device: mps
1.13.0.dev20220614
0.14.0.dev20220614
Traceback (most recent call last):
File "Disco_Diffusion_v5_2_m1.py", line 2340, in <module>
do_run()
File "Disco_Diffusion_v5_2_m1.py", line 983, in do_run
txt = clip_model.encode_text(clip.tokenize(prompt).to(device)).float()
File "/Users/aiden/notebook/CLIP/clip/model.py", line 355, in encode_text
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
const Tensor& self,
const at::MaterializedIOptTensorListRef& indices) {
auto dev = self.device();
bool indices_on_cpu_or_dev = std::all_of(
indices.begin(), indices.end(), [=](const at::OptionalTensorRef& opt) {
return opt.has_value() ? (opt->is_cpu() || opt->device() == dev) : true;
});
TORCH_CHECK(
indices_on_cpu_or_dev,
"indices should be either on ", kCPU,
" or on the same device as the indexed tensor (", dev, ")");
}
TORCH_PRECOMPUTE_META_FUNC2(index, Tensor)
(const Tensor& self, at::IOptTensorListRef indices) {
auto materialized = indices.materialize();
TORCH_CHECK_INDEX(
materialized.size() <= (size_t)self.dim(),
"too many indices for tensor of dimension ",
self.dim(), " (got ", materialized.size(), ")");
albanD
June 15, 2022, 8:10pm
2
Can you make sure that all the Tensors are on the same device?torch.arange(size, device=x.device) to make sure it matches.
albanD:
, device=x.device
print("+++++++++++++++")
print(x.device)
print(text.device)
print(self.text_projection.device)
print("+++++++++++++++")
They are all on device mps:0
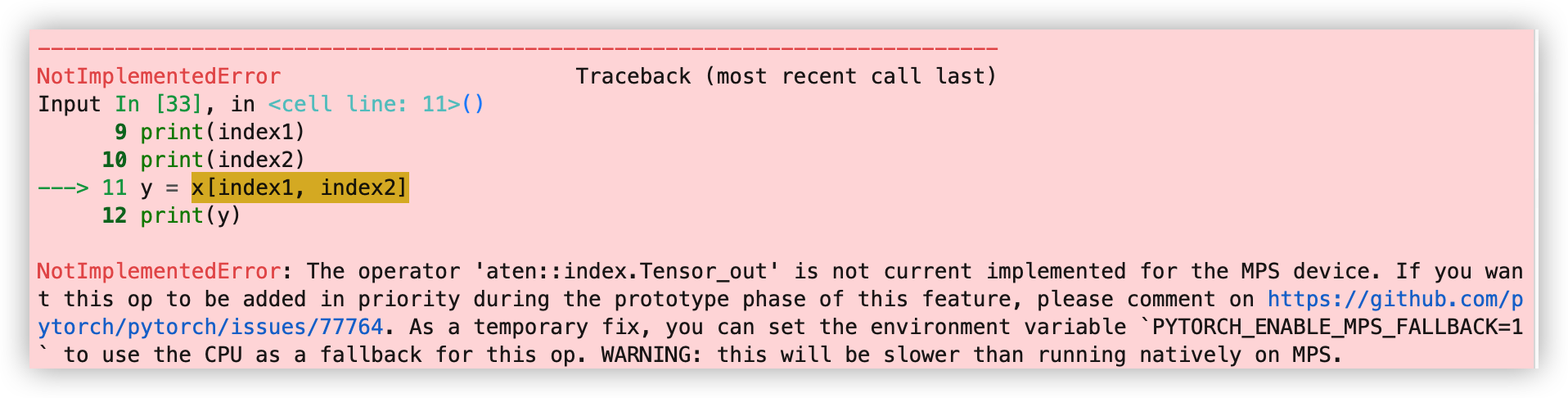
import numpy as np
x = torch.arange(72, dtype=torch.float32).to(device)
x = x.reshape((6,3,4))
print(x)
print(x.device)
index1 = torch.arange(1).to(device)
index2 = torch.arange(1).to(device)
index2[0] = 5
print(index1)
print(index2)
y = x[index1, index2]
print(y)
NotImplementedError: The operator 'aten::index.Tensor_out' is not current implemented for the MPS device. If you want this op to be added in priority during the prototype phase of this feature, please comment on https://github.com/pytorch/pytorch/issues/77764. As a temporary fix, you can set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU as a fallback for this op. WARNING: this will be slower than running natively on MPS.
‘aten::index.Tensor_out’ triggers fallback to cpu.
opened 06:12PM - 18 May 22 UTC
feature
triaged
module: mps
### This issue is to have a centralized place to list and track work on adding s… upport to new ops for the MPS backend.
[**MPS operators coverage matrix**](https://qqaatw.github.io/pytorch-mps-ops-coverage/) - The matrix covers most of the supported operators but is not exhaustive. Before you comment below, please take a look at this matrix to make sure the operator you're requesting has not been implemented in nightly. More details can be found on the [readme](https://github.com/qqaatw/pytorch-mps-ops-coverage).
There are a very large number of operators in pytorch and so they are not all implemented yet for the MPS backends as it is still in the prototype phase. We will be prioritizing adding new operators based on user feedback. If possible, please also provide link to the network or use-case where this op is getting used.
If you want to work on adding support for such op, feel free to comment below to get assigned one. Please avoid pickup up an op that is already being worked on or that already has a PR associated with it.
[Link to the wiki for details](https://github.com/pytorch/pytorch/wiki/MPS-Backend) on how to add these ops and example PRs.
**Good First Issue:**
Below is list of Ops which are good to get started to add operations to MPS backend. Please consider picking them up.
- [ ] `nn.Conv3D`
- [ ] `aten::_weight_norm_interface`
- [ ] `aten::max_unpool2d`
- [ ] `aten::cummin.out`, `aten::cummax.out`
- [ ] `aten::upsample_linear1d.out`
- [ ] `aten::lerp.Scalar_out`
- [ ] `aten::renorm`
**Not categorized:**
These are the ops which are not yet picked up and need MPS implementation.
- [ ] `aten::slow_conv3d_forward`
- [ ] `aten::_ctc_loss`
- [ ] `aten::avg_pool3d.out`
- [ ] `aten::linalg_qr.out`
- [ ] `aten::multilabel_margin_loss_forward`
- [ ] `aten::unique_dim`
- [ ] `aten::_sample_dirichlet`
- [ ] `aten::_fft_r2c`
- [ ] `aten::upsample_bicubic2d.out`
- [ ] `aten::linalg_inv_out_helper`
- [ ] `aten::bucketize`
- [ ] `aten::_embedding_bag`
- [ ] `aten::_standard_gamma`
- [ ] `aten::_upsample_bicubic2d_aa.out`
- [ ] `aten::'aten::_symeig_helper`
- [ ] `aten::linalg_matrix_exp`
- [ ] `aten::_nested_tensor_from_mask`
- [ ] `aten::randperm.generator_out`
- [ ] `aten::_fused_sdp_choice`
- [ ] `aten::linalg_cholesky_ex`
- [ ] `aten::scatter_reduce.two_out`
- [ ] `aten::kthvalue.values`
- [ ] `aten::_linalg_solve_ex.result`
- [ ] `aten::grid_sampler_2d_backward'`
**WIP:**
- [ ] `max_pool3d` https://github.com/pytorch/pytorch/pull/102148
- [ ] `aten::kl_div_backward` (Is not needed )
**Implemented Ops:**
Ops that have MPS backend implementations.
See [**MPS operators coverage matrix**](https://qqaatw.github.io/pytorch-mps-ops-coverage/) and the [readme](https://github.com/qqaatw/pytorch-mps-ops-coverage) for more details.
<details>
<summary>deprecated list</summary>
- [x] `aten::histc` #96652
- [x] `pow.Scalar_out` (@qqaatw )
- [x] `aten::log_sigmoid_forward` (@qqaatw )
- [x] `aten::fmax.out` (@qqaatw )
- [x] `aten::roll` https://github.com/pytorch/pytorch/pull/95168
- [x] `aten::hardsigmoid` (@qqaatw )
- [x] `aten::logit` (@qqaatw )
- [x] `linalg_solve_triangular`
- [x] `aten::sort.values_stable` https://github.com/pytorch/pytorch/issues/86750
- [x] `aten::remainder.Tensor_out` https://github.com/pytorch/pytorch/issues/86806
- [x] `aten::hardswish` https://github.com/pytorch/pytorch/issues/86807
- [x] `aten::nansum` https://github.com/pytorch/pytorch/issues/86809
- [x] `aten::fmod.Tensor_out` https://github.com/pytorch/pytorch/issues/86810
- [x] `aten::range` https://github.com/pytorch/pytorch/issues/86990
- [x] `aten::argsort` https://github.com/pytorch/pytorch/issues/86991
- [x] `aten::repeat_interleave` https://github.com/pytorch/pytorch/issues/87219
- [x] `aten::median` https://github.com/pytorch/pytorch/issues/87220
- [x] `aten::trace` https://github.com/pytorch/pytorch/issues/87221
- [x] `aten::im2col` (Falling back to CPU as its mostly used in preprocessing layers)
- [x] `aten::_cdist_forward` https://github.com/pytorch/pytorch/pull/91643
- [x] `aten::native_group_norm_backward` (Implemented by @malfet )
- [x] `aten::grid_sampler_2d` (https://github.com/pytorch/pytorch/pull/94273)
- [x] `aten::upsample_nearest1d_backward.grad_input`
- [x] `aten::upsample_nearest1d.out`
- [x] `aten::repeat_interleave.self_int`
- [x] `aten::nan_to_num.out`
- [x] `aten::unique_consecutive` https://github.com/pytorch/pytorch/pull/88532
- [x] `torch.bincount` https://github.com/pytorch/pytorch/pull/91267
- [x] `aten::_unique2` https://github.com/pytorch/pytorch/pull/88532
- [x] `aten::unfold` https://github.com/pytorch/pytorch/pull/91266
- [x] `aten::triangular_solve.X` https://github.com/pytorch/pytorch/pull/94345
- [x] `aten::nonzero` https://github.com/pytorch/pytorch/pull/91616
- [x] `aten::_index_put_impl_` (https://github.com/pytorch/pytorch/pull/85672)
- [x] `aten::amax.out` (#79682)
- [X] `aten::_slow_conv2d_forward` (https://github.com/pytorch/pytorch/pull/86303)
- [x] `aten::eye.m_out` (https://github.com/pytorch/pytorch/pull/78408)
- [x] `aten::multinomial` (https://github.com/pytorch/pytorch/pull/80760 )
- [x] `aten::flip` (#80214)
- [x] `aten::equal` https://github.com/pytorch/pytorch/pull/80195
- [x] `aten::_local_scalar_dense`
- [x] `aten::l1_loss_backward.grad_input` (#80010)
- [x] `aten::glu.out` (#79866)
- [x] ` aten::linspace.out` https://github.com/pytorch/pytorch/pull/78570
- [x] `aten::arange.out` https://github.com/pytorch/pytorch/pull/78789
- [x] `aten::adaptive_max_pool2d` https://github.com/pytorch/pytorch/pull/78410
- [x] `aten::count_nonzero.dim_IntList`
- [x] `aten::softplus.out` (https://github.com/pytorch/pytorch/pull/78930)
- [x] `aten::index_add.out` https://github.com/pytorch/pytorch/pull/79935
- [x] `aten::normal` (#80297)
- [x] `aten::native_layer_norm_backward` https://github.com/pytorch/pytorch/pull/79189
- [x] `aten::logical_and.out` (#80216)
- [x] `aten::frac.out` (https://github.com/pytorch/pytorch/pull/86625)
- [x] `aten:: masked_select` https://github.com/pytorch/pytorch/pull/85818
- [x] `aten::softplus_backward.grad_input` (#79873)
- [x] `aten::slow_conv_transpose2d.out` (@malfet could be due to incompatibility with torchvision)
- [x] `aten::signbit.out` (https://github.com/pytorch/pytorch/pull/87214)
- [X] `aten::cumsum.out` (https://github.com/pytorch/pytorch/pull/88319)
- [X] `aten::cumprod.out`
- [X] `aten::expm1.out` (https://github.com/pytorch/pytorch/pull/87147)
- [x] `aten::bitwise_xor.Tensor_out` (https://github.com/pytorch/pytorch/pull/82307)
- [x] `aten::bitwise_and.Tensor_out` (https://github.com/pytorch/pytorch/pull/82307)
- [x] `aten::bitwise_or.Tensor_out` (https://github.com/pytorch/pytorch/pull/82307)
- [x] `aten::index.Tensor` (https://github.com/pytorch/pytorch/pull/82507)
- [x] `aten::index.Tensor_out` (https://github.com/pytorch/pytorch/pull/82507)
</details>
**Ops not supported by MPS:**
Ops that will require either to use the CPU fallback system or a custom Metal kernel.
- [ ] `aten::lgamma.out`
- [ ] `aten::linalg_householder_product`