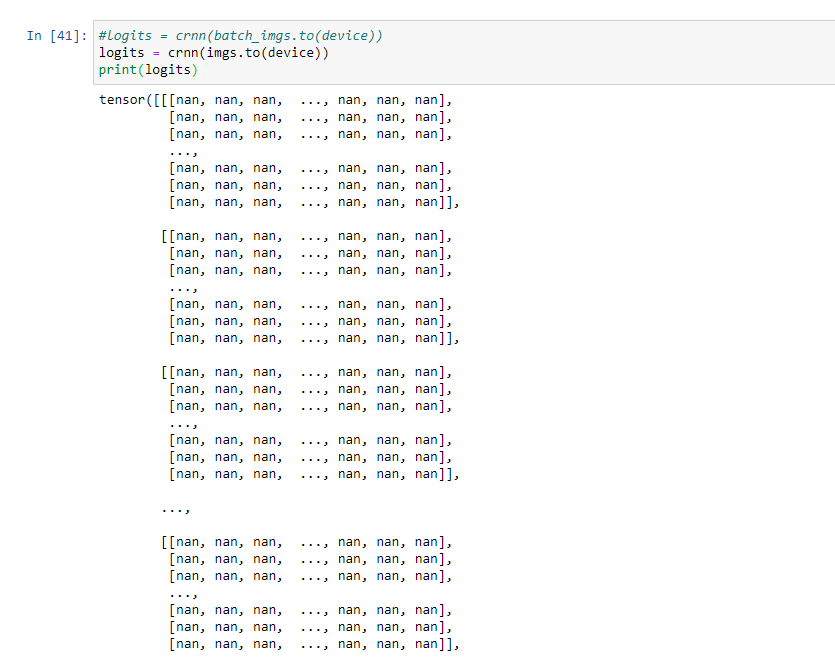
Hello, I’m using the CRNN architecture from GitHub - carnotaur/crnn-tutorial: Training Convolutional Recurrent Neural Network (CRNN) using PyTorch for a OCR app, I’m also using custom data, but when the training begins, I got this:

here some snippets from my notebook:
class CaptchaDataset(Dataset):
def __init__(self, img_dir: str):
pathes = os.listdir(img_dir)
abspath = os.path.abspath(img_dir)
self.img_dir = img_dir
self.pathes = [os.path.join(abspath, path) for path in pathes]
self.list_transforms = transforms.Compose([transforms.Resize((50, 200)), transforms.ToTensor()])
def __len__(self):
return len(self.pathes)
def __getitem__(self, idx):
labels = '../datasets/labels'
path = self.pathes[idx]
name = self.get_file_name(path)
full_path= os.path.dirname(os.path.abspath(path))
label_path = labels + '/' + name + '.txt'
text = self.get_current_index_label(label_path)
img = Image.open(path).convert('RGB')
img = self.transform(img)
return img, text
def get_current_index_label(self, path):
ext = os.path.basename(path).split('.')[1].lower().strip()
f = open(path, 'r')
contents = f.read()
return str(contents)
def transform(self, img) -> torch.Tensor:
return self.list_transforms(img)
def get_file_name(self, path: str) -> str:
return os.path.basename(path).split('.')[0].lower().strip()
alphabet = """abcdefghijklmnñopqrstuvwxyz0123456789()_,.:*/'-ÃD#±+@ """
label_converter = strLabelConverter(alphabet)
alphabet
hidden_size = 256
vocab_size = len(alphabet) # extra character for blank symbol
bidirectional = True
dropout = 0.1
weight_decay = 1e-5
momentum = 0.9
clip_norm = 5
max_epoch = 50
print(vocab_size)
imgs, texts = iter(val_dataloader).next()
print(imgs.shape, len(texts))
torch.Size([8, 3, 50, 200]) 8
def weights_init(m):
classname = m.__class__.__name__
if type(m) in [nn.Linear, nn.Conv2d, nn.Conv1d]:
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
class CRNN(nn.Module):
def __init__(self, hidden_size: int,
vocab_size: int,
bidirectional: bool = True,
dropout: float = 0.5):
super(CRNN, self).__init__()
self.hidden_size = hidden_size
self.vocab_size = vocab_size
self.bidirectional = bidirectional
# make layers
# convolutions
resnet = resnet18(pretrained=True)
modules = list(resnet.children())[:-3]
self.resnet = nn.Sequential(*modules)
self.cn6 = blockCNN(256, 256, kernel_size=3, padding=1)
# RNN + Linear
self.linear1 = nn.Linear(1024, 256)
self.gru1 = blockRNN(256, hidden_size, hidden_size,
dropout=dropout,
bidirectional=bidirectional)
self.gru2 = blockRNN(hidden_size, hidden_size, vocab_size,
dropout=dropout,
bidirectional=bidirectional)
self.linear2 = nn.Linear(hidden_size * 2, vocab_size)
def forward(self, batch: torch.Tensor):
"""
------:size sequence:------
torch.Size([batch_size, 3, 50, 200]) -- IN:
torch.Size([batch_size, 256, 4, 13]) -- CNN blocks ended
torch.Size([batch_size, 13, 256, 4]) -- permuted
torch.Size([batch_size, 13, 1024]) -- Linear #1
torch.Size([batch_size, 13, 256]) -- IN GRU
torch.Size([batch_size, 13, 256]) -- OUT GRU
torch.Size([batch_size, 13, vocab_size]) -- Linear #2
torch.Size([13, batch_size, vocab_size]) -- :OUT
"""
batch_size = batch.size(0)
# convolutions
batch = self.resnet(batch)
batch = self.cn6(batch, use_relu=True, use_bn=True)
# make sequences of image features
batch = batch.permute(0, 3, 1, 2)
n_channels = batch.size(1)
batch = batch.view(batch_size, n_channels, -1)
batch = self.linear1(batch)
# rnn layers
batch = self.gru1(batch, add_output=True)
batch = self.gru2(batch)
# output
batch = self.linear2(batch)
batch = batch.permute(1, 0, 2)
return batch
crnn = CRNN(hidden_size=hidden_size, vocab_size=vocab_size,
bidirectional=bidirectional, dropout=dropout).to(device)
crnn(imgs.to(device)).shape
lr = 0.01
optimizer = torch.optim.SGD(crnn.parameters(), lr=lr, nesterov=True,
weight_decay=weight_decay, momentum=momentum)
critertion = nn.CTCLoss(blank=0)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, verbose=True, patience=5)
def validation(model, val_losses, label_converter):
with torch.no_grad():
model.eval()
for batch_img, batch_text in val_dataloader:
logits = crnn(batch_img.to(device))
val_loss = calculate_loss(logits, batch_text, label_converter)
val_losses.append(val_loss.item())
return val_losses
def calculate_loss(logits, texts, label_converter):
# get infomation from prediction
device = logits.device
input_len, batch_size, vocab_size = logits.size()
# encode inputs
logits = logits.log_softmax(2)
encoded_texts, text_lens = label_converter.encode(texts)
logits_lens = torch.full(size=(batch_size,), fill_value=input_len, dtype=torch.int32)
# calculate ctc
loss = critertion(logits, encoded_texts,
logits_lens.to(device), text_lens)
return loss
train_losses = []
val_losses = []
val_epoch_len = len(val_dataset) // BATCH_SIZE
val_epoch_len
try:
while epoch <= max_epoch:
crnn.train()
for idx, (batch_imgs, batch_text) in enumerate(train_dataloader):
optimizer.zero_grad()
logits = crnn(batch_imgs.to(device))
# calculate loss
train_loss = calculate_loss(logits, batch_text, label_converter)
if np.isnan(train_loss.detach().cpu().numpy()):
continue
train_losses.append(train_loss.item())
# make backward
train_loss.backward()
nn.utils.clip_grad_norm_(crnn.parameters(), clip_norm)
optimizer.step()
val_losses = validation(crnn, val_losses, label_converter)
# printing progress
plot_loss(epoch, train_losses, val_losses)
print_prediction(crnn, val_dataset, device, label_converter)
scheduler.step(val_losses[-1])
epoch += 1
except KeyboardInterrupt:
pass`Preformatted text` ```
please help.