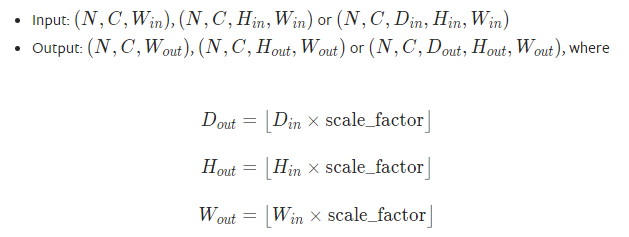Thanks, @Matias_Vasquez. I think the layer name should be torch.nn.Resample.
I like to know how torch.nn.Upsample works for downsampling. In the depth part of volumetric data, it might be hard to decide the appropriate strategy to drop the slices depending on the domain.
For example, in medical data, if we drop the slice blindly, we might lose information. I mean, in CT/MRI images, most of the slice information appears mainly in the middle range of depth.
a = torch.rand(3, 3, 40, 256, 256)
down = torch.nn.Upsample(size=(20, 128, 128))
torch.Size([3, 3, 20, 128, 128])
So, how does 40 becomes 20. Which slices are dropped?
This is what you need to decide when you give the mode parameter. The default value (if you do not specify) is nearest.
For the case where you divide the size by 2, means that every even (or uneven) row/column will be dropped and the value will be taken from the nearest values. Which would be the actual value of the row/column that is not deleted. If you choose something like bilinear then a line will be computed from voxel to voxel and the value in between will be chosen.
However, if you say that the most important information is in the middle, then you can slice your data first. This way you will select the parts that matter the most to you and retaining more valuable information.
After slicing you can then still downsample, but less data will be lost in order to get the same size.
Since the scaling factor will be smaller (not dividing by 2 but 1.5 for example) then the values will be computed depending on the mode selected.