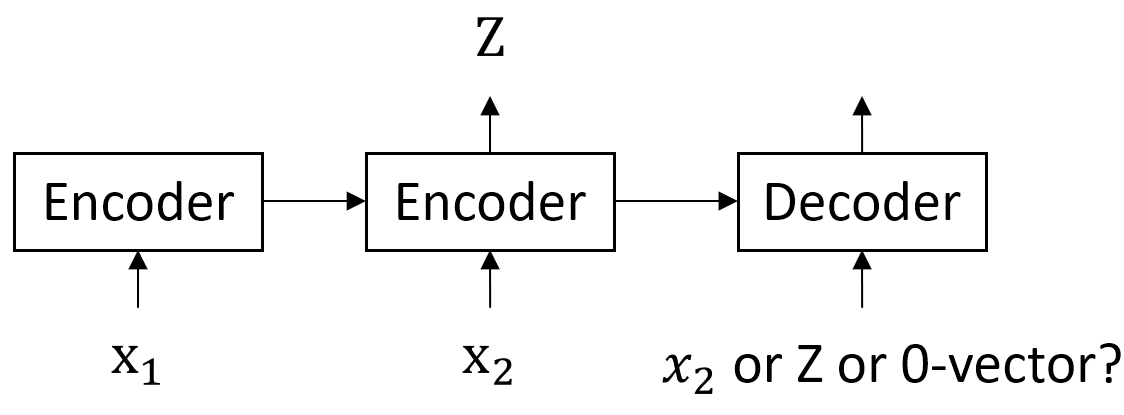
I am working on future frame prediction using an encoder-decoder RNN. I read online that the input of the decoder is supposed to be the output at the previous timestep. What about at time t=0? In the figure below, should the input to the decoder at the 1st timestep be the frame x2 or the output of the encoder or a 0 vector?