I have some questions with pytorch that I can’t find an answer to for days. so any help is appreciated
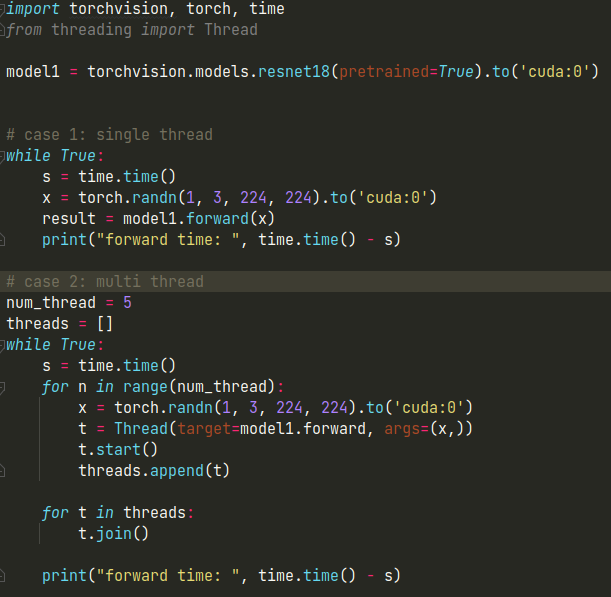
In example, i have a simple pytorch model, loaded on GPU. What happens when multiple threads call the model at the same time? why doesn’t the speed increase compared to the case of single thread ? What is the order of execution on gpu when there are multiple thread/process ?
case 1: forward time: ~0.05s, gpu utils: ~25%
case 2: 5 thread calling the model: forward time: ~0.25s, gpu utils ~25%
As I noticed that multithreading does not increase the speed nor gpu ultis of the model, i try to create another instance of model to run multiple instance of models at the same time. but on gpu memory it seems the model is not reinitialized same as cpu case.
case 1: memory (RAM) usage of two model is doubled vs single model.
case2: GPU memory usage of two model is same as single model.
So what is different when model is init on gpu, Why gpu memory usage is not increasing ?
How to initialize multiple instances of model on gpu to run them at same time to increase gpu ultilization ?
The order of execution is defined by the kernel scheduling from multiple streams. Since you are launching all kernels in the same stream, no parallel execution will be performed. Even if you are using separate CUDA streams, your device would need to have free compute resources to be able to execute kernels in parallel.
The GPU memory does increase in the second example:
thanks you for your helpful reply! I understand a little more now. There are some questions I would like to ask you in more depth
So the stream is decided by the program or what factors ? According to what I read in docs, the stream is decided by torch.devices, each GPU (hardware level ?) has a default stream. But when i run 2 same python programs on single GPU, gpu is correctly in double usage (25 → 50%). if so, is it that 2 different programs will use 2 different “default streams” of a hardware gpu ?
yes that true, thanks you. i checked back, and gpu alloc for the model is only 46mb, but first initialization eat 800mb vram that i guessed because of cuda context, so i do not notice the memory increase
Can i ask you one more question: So when i want to do parallel execution to maximize the gpu utils, is it better to use one model instance and multiple cuda stream, or multiple instances (take more VRAM) with multiple cuda stream ?
and can you give me an example to be able to run multiple excecution on gpu concurrently with cuda streams (with simple models as above)
Thank you again!
Here is a simple example, but note that you cannot expect to execute different workloads in parallel just by using different Streams.
If the operations on a single stream already saturate the GPU and its compute resources you won’t be able to launch any more work.