Hi all,
Here, I’ll report a crazy-to-find ‘bug’ in case this can save time for someone.
For our work on improving training for seq2seq models (SEARNN: https://arxiv.org/abs/1706.04499), we faced a difficulty while implementing machine translation. The behaviour of the pytorch implementation was significantly different from the reference TF code. The pytorch version was converging significantly slower in terms of the number iterations needed to achieve the same BLEU on validation. However, working with pytorch was very beneficial because we could implement a runnable version of our method ![]() (the TF was very slow for some unknown reasons).
(the TF was very slow for some unknown reasons).
It took ages to investigate the discrepancy and in the end we had to align the two codes step by step to make sure the models produced identical gradients for identical inputs (there were a lot of difficulties because of, e.g., different versions of the GRU cells were used).
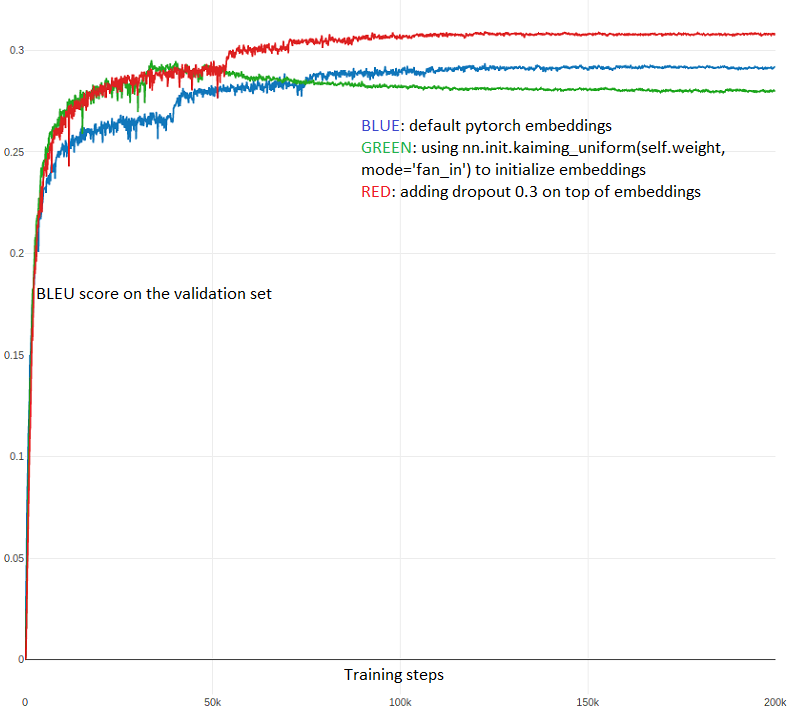
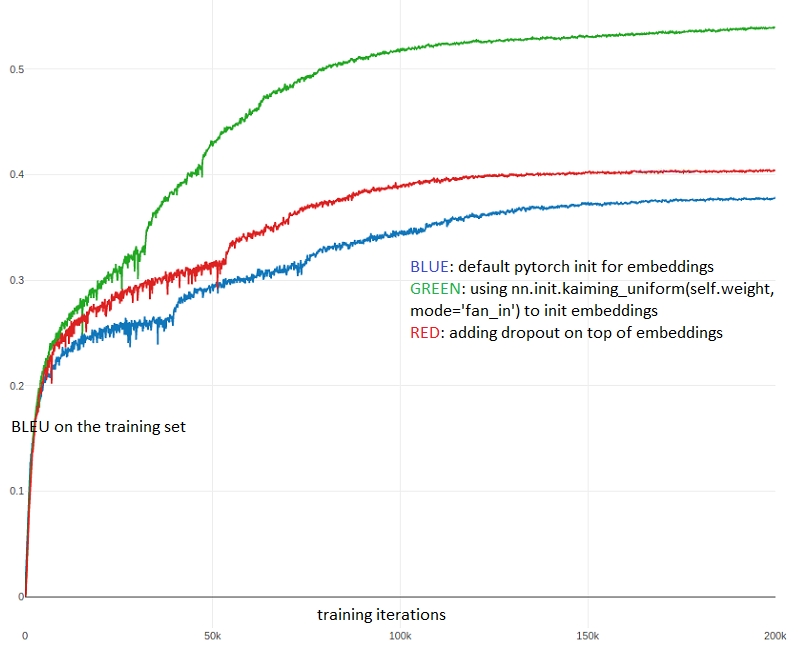
In the end of the day, it appeared that the key difference was hiding in the initialization of embeddings. In pytorch, the embeddings are initialized form the standard Gaussians by default. In TF, it seemed the case as well, but they were not actually using the embedding layer. In the linear layer that was actually used, the default initialization was glorot/xavier, which was the silent game changer!
Trying this solved the discrepancy between the codes and boosted our results quite a bit. We converged to using torch.nn.init.kaiming_uniform, because it results in embeddings with scale independent of the dictionary size (and worked a bit better). We observed that changing init helped the optimization a lot and the method started overfitting more. Extra regularization (dropout) fixed this and overall results became significantly better.
Below, I report the confirmation experiment, with the three versions of embeddings:
- the default pytorch embeddings;
- the version with torch.nn.init.kaiming_uniform(…, mode=‘fan_in’);
- the kaiming embedding with extra dropout on top.
Hope this will save someone’s time!
Best,
Anton