Hi,
I have sequence data, which are technically measurements from an IMU, which are taken between each camera image frame. I want to pass them through a many-to-one LSTM-Module.
The sequence has the dimension [S_out x B x S_in x N], S_out are the number of frames, B is the batch size, S_in is the number of measurements between each image frame and at least N are the actual measurement values. In this particular case we have:
S_out = 4
B = 8
S_in = 10
N = 6
the pseudo-code for training is:
preds = [outer-seq-size]
for s=1 : outer-seq-size:
preds[s] = model(x[s])
loss = clac_loss(preds, gts)
loss.backward()
....
model.reset_hidden_states()
My LSTM-Module is:
class ImufeatRNN0(BaseImuFeatNet):
def __init__(self, cfg):
self.rnn = nn.LSTM(input_size=6, hidden_size=128,
num_layers=2, bidirectional=False, dropout=0.)
self.num_dir = 1
self.reset_hidden_states()
def reset_hidden_states(self):
self.h = None
self.c = None
def forward(self, x):
x_padded = nn.utils.rnn.pad_sequence(x)
s, b, n = x_padded.shape # seq
if self.h is None:
out, (self.h, self.c) = self.rnn(x_padded, None)
else:
out, (self.h, self.c) = self.rnn(x_padded, (self.h, self.c))
out = out.view(s, b, self.num_dir, 128)
out = out[-1, :, 0].contiguous().squeeze() # many-to-one
return out
The fig. below should make the situation more clear.
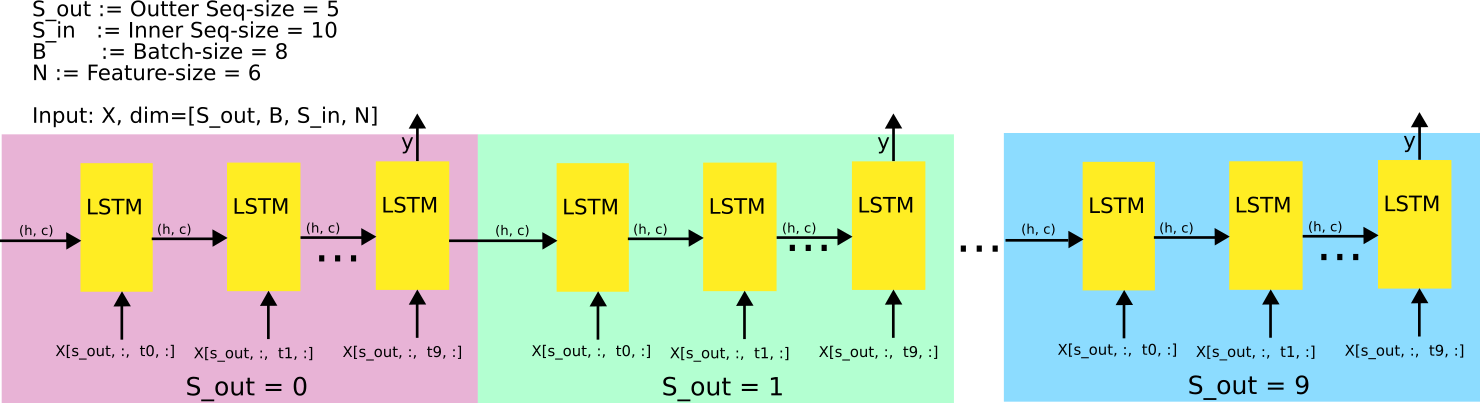
But every time I run the code I get this error:
File “/home/ajava/Projects/DeepLIO/deeplio/models/nets/imu_feat_nets.py”, line 86, in forward
out, (self.h, self.c) = self.rnn(x_padded, (self.h, self.c))
File “/opt/miniconda3/envs/env_master/lib/python3.7/site-packages/torch/nn/modules/module.py”, line 532, in call
result = self.forward(*input, **kwargs)
File “/opt/miniconda3/envs/env_master/lib/python3.7/site-packages/torch/nn/modules/rnn.py”, line 559, in forward
self.dropout, self.training, self.bidirectional, self.batch_first)
(print_stack at /opt/conda/conda-bld/pytorch_1579022060824/work/torch/csrc/autograd/python_anomaly_mode.cpp:57)
Traceback (most recent call last):
File “/home/ajava/Projects/DeepLIO/deeplio/train.py”, line 67, in
trainer.run()
File “/home/ajava/Projects/DeepLIO/deeplio/models/trainer.py”, line 135, in run
self.train(epoch)
File “/home/ajava/Projects/DeepLIO/deeplio/models/trainer.py”, line 250, in train
loss.backward(retain_graph=False)
File “/opt/miniconda3/envs/env_master/lib/python3.7/site-packages/torch/tensor.py”, line 195, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File “/opt/miniconda3/envs/env_master/lib/python3.7/site-packages/torch/autograd/init.py”, line 99, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [11, 8, 128]], which is output 0 of CudnnRnnBackward, is at version 1; expected version 0 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
Update
The problem is that changing the shape of the ‘out’-variable is an in-place operation, detaching it removes the error message:
out = out.view(s, b, self.num_dir, self.hidden_size)
y = out[-1, :, 0].contiguous().squeeze().detach() # many-to-one
return y
But can anyone plz tell me, is that the correct way? What happens to the loss which is calc. using detached output? Is the computational graph still valid?
Thanks