the model is the following
class Yolo(nn.Module):
def __init__(self, grid_size, num_boxes, num_classes):
super(Yolo, self).__init__()
self.S = grid_size
self.B = num_boxes
self.C = num_classes
self.features = nn.Sequential(
# P1.1. implement VGG16 backbone network here.
nn.Conv2d(3,64,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.Conv2d(64,64,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0,dilation=1,ceil_mode = False),
nn.Conv2d(64,128,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.Conv2d(128,128,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0,dilation=1,ceil_mode = False),
nn.Conv2d(128,256,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.Conv2d(256,256,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.Conv2d(256,256,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0,dilation=1,ceil_mode = False),
nn.Conv2d(256,512,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.Conv2d(512,512,3,1,1),
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.Conv2d(512,512,3,1,1),
# nn.ReLU(inplace=True),
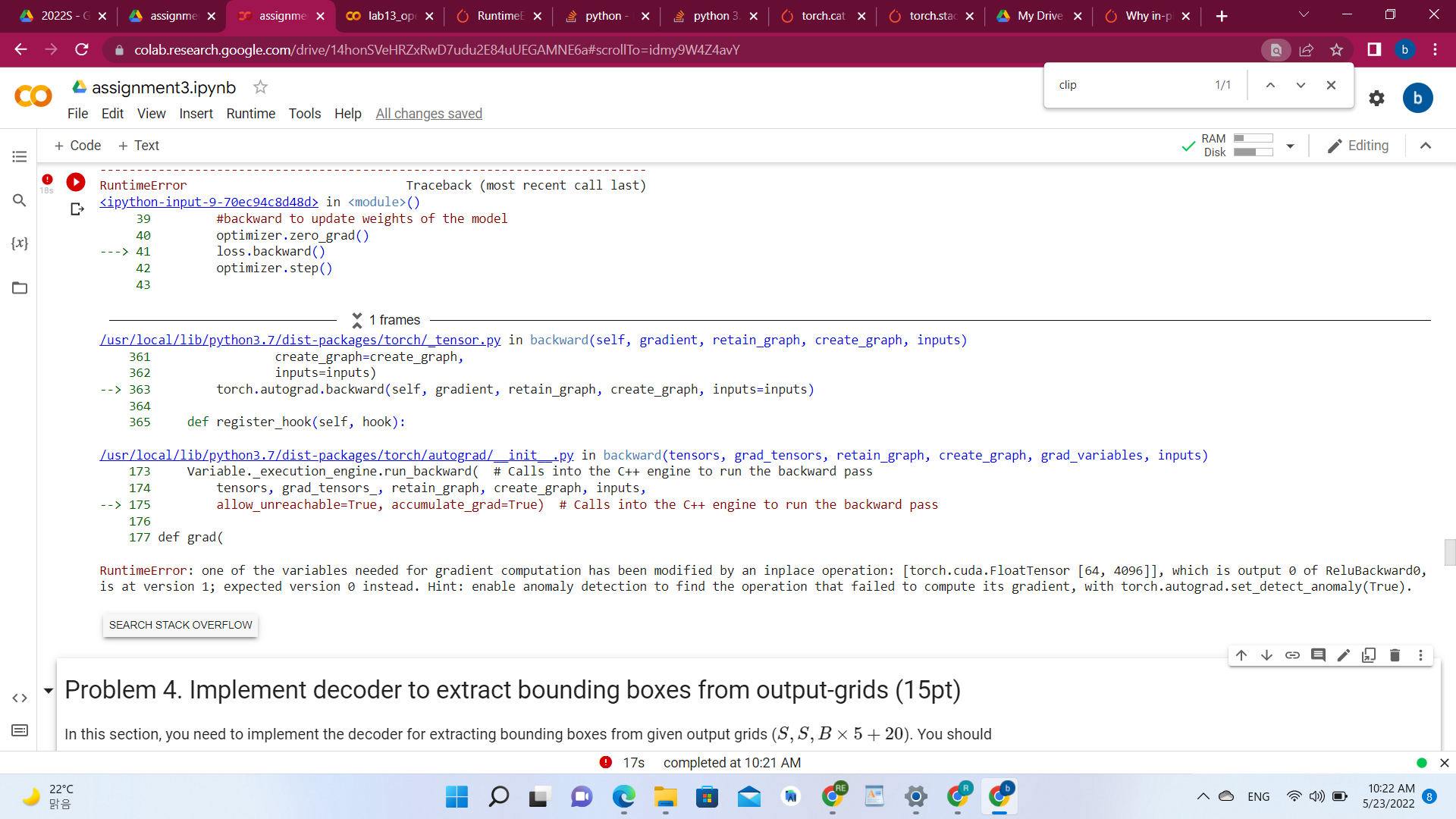
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0,dilation=1,ceil_mode = False),
nn.Conv2d(512,512,3,1,1),
# nn.ReLU(inplace = True),
nn.ReLU(inplace=False),
nn.Conv2d(512,512,3,1,1),
# nn.ReLU(inplace = True),
nn.ReLU(inplace=False),
nn.Conv2d(512,512,3,1,1),
# nn.ReLU(inplace = True),
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0,dilation=1,ceil_mode = False),
)
self.detector = nn.Sequential(
# P1.2. implement detection head here.
nn.Linear(25088,4096,bias=True), #how do i know the in_feature??
# nn.ReLU(inplace=True),
nn.ReLU(inplace=False),
nn.Dropout(p=0.5,inplace=True),
nn.Linear(4096,1470,bias=True)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.detector(x)
x = F.sigmoid(x)
x = x.view(-1, self.S, self.S, self.B*5+self.C)
return x
model = Yolo(grid_size, num_boxes, num_classes)
model = model.to(device)
pretrained_weights = torch.load(pretrained_backbone_path)
model.load_state_dict(pretrained_weights)
and the follwing function shows the loss function used in the training process
class Loss(nn.Module):
def __init__(self, grid_size=7, num_bboxes=2, num_classes=20):
""" Loss module for Yolo v1.
Use grid_size, num_bboxes, num_classes information if necessary.
Args:
grid_size: (int) size of input grid.
num_bboxes: (int) number of bboxes per each cell.
num_classes: (int) number of the object classes.
"""
super(Loss, self).__init__()
self.S = grid_size
self.B = num_bboxes
self.C = num_classes
def compute_iou(self, bbox1, bbox2):
""" Compute the IoU (Intersection over Union) of two set of bboxes, each bbox format: [x1, y1, x2, y2].
Use this function if necessary.
Args:
bbox1: (Tensor) bounding bboxes, sized [N, 4].
bbox2: (Tensor) bounding bboxes, sized [M, 4].
Returns:
(Tensor) IoU, sized [N, M].
"""
N = bbox1.size(0)
M = bbox2.size(0)
# Compute left-top coordinate of the intersections
lt = torch.max(
bbox1[:, :2].unsqueeze(1).expand(N, M, 2), # [N, 2] -> [N, 1, 2] -> [N, M, 2]
bbox2[:, :2].unsqueeze(0).expand(N, M, 2) # [M, 2] -> [1, M, 2] -> [N, M, 2]
)
# Conpute right-bottom coordinate of the intersections
rb = torch.min(
bbox1[:, 2:].unsqueeze(1).expand(N, M, 2), # [N, 2] -> [N, 1, 2] -> [N, M, 2]
bbox2[:, 2:].unsqueeze(0).expand(N, M, 2) # [M, 2] -> [1, M, 2] -> [N, M, 2]
)
# Compute area of the intersections from the coordinates
wh = rb - lt # width and height of the intersection, [N, M, 2]
wh[wh < 0] = 0 # clip at 0
inter = wh[:, :, 0] * wh[:, :, 1] # [N, M]
# Compute area of the bboxes
area1 = (bbox1[:, 2] - bbox1[:, 0]) * (bbox1[:, 3] - bbox1[:, 1]) # [N, ]
area2 = (bbox2[:, 2] - bbox2[:, 0]) * (bbox2[:, 3] - bbox2[:, 1]) # [M, ]
area1 = area1.unsqueeze(1).expand_as(inter) # [N, ] -> [N, 1] -> [N, M]
area2 = area2.unsqueeze(0).expand_as(inter) # [M, ] -> [1, M] -> [N, M]
# Compute IoU from the areas
union = area1 + area2 - inter # [N, M, 2]
iou = inter / union # [N, M, 2]
return iou
def forward(self, pred_tensor, target_tensor):
""" Compute loss.
Args:
pred_tensor (Tensor): predictions, sized [batch_size, S, S, Bx5+C], 5=len([x, y, w, h, conf]).
target_tensor (Tensor): targets, sized [batch_size, S, S, Bx5+C].
Returns:
loss_xy (Tensor): localization loss for center positions (x, y) of bboxes.
loss_wh (Tensor): localization loss for width, height of bboxes.
loss_obj (Tensor): objectness loss.
loss_noobj (Tensor): no-objectness loss.
loss_class (Tensor): classification loss.
"""
# P2. Write your code here
grid = self.S
num_box = self.B
num_class = self.C
N = 5*num_box + 5
# get masks for cells which contain and those which don't contain objects
no_obj = target_tensor[...,4]==0
no_obj = no_obj.unsqueeze(3).expand_as(target_tensor)
exists_obj = target_tensor[...,4]>0
exists_obj = exists_obj.unsqueeze(3).expand_as(target_tensor)
########CELLS WITH NO_OBJECT################################
# prediction tensors and target tensors on cells which don't contain objects
no_obj_target = target_tensor[no_obj].view(-1,N)
no_obj_prediction = pred_tensor[no_obj].view(-1,N)
########CELLS WITH OBJECT################################
obj_prediction = pred_tensor[exists_obj].view(-1,N)
obj_target = target_tensor[exists_obj].view(-1,N)
bounding_box_prediction = obj_prediction[...,:5*num_box].contiguous().view(-1,5)
# bbox_prediction = bounding_box_predition.contiguous().view(-1,5)
bounding_box_target = obj_target[...,:5*num_box].contiguous().view(-1,5)
# bbox_target = bounding_box_target.contiguous().view(-1,5)
############# USE IoU FOR PREDICTING THE BBOX FOR EACH CELL ###
### masks for coordinates
obj_res = torch.cuda.ByteTensor(bounding_box_target.size()).fill_(0)
obj_nres = torch.cuda.ByteTensor(bounding_box_target.size()).fill_(1)
bounding_box_target_iou = torch.zeros(bounding_box_target.size()).to(device)
for i in range(0,bounding_box_target.size(0),num_box):
prediction_box = bounding_box_prediction[i:i+num_box]
prediction_xyxy = Variable(torch.FloatTensor(prediction_box.size()))
# to compute iou correctly lets change the structure(x,y,w,h)->(x1,y1,w,h) while normalizing them simultaneously
prediction_xyxy[...,:2] = prediction_box[...,:2]/float(grid) - prediction_box[...,2:4]/2
prediction_xyxy[...,2:4] = prediction_box[...,:2]/float(grid) + prediction_box[...,2:4]/2
target_box = bounding_box_target[i]
target_box = bounding_box_target[i].view(-1,5)
target_xyxy = Variable(torch.FloatTensor(target_box.size()))
# to compute iou correctly lets change the structure(x,y,w,h)->(x1,y1,w,h) while normalizing them simultaneously
target_xyxy[...,:2] = target_box[...,:2]/float(grid) - target_box[...,2:4]/2
target_xyxy[...,2:4] = target_box[...,:2]/float(grid) + target_box[...,2:4]/2
#let's now calculate intersection over union
inter_ovr_un = self.compute_iou(prediction_xyxy[...,:4],target_xyxy[...,:4])
max_iou,max_index = inter_ovr_un.max(0)
max_index = max_index.data.to(device)
obj_res[i+max_index], obj_nres[i+max_index] = 1,0
bounding_box_target_iou[i+max_index,torch.LongTensor([4]).to(device)] = max_iou.data.to(device)
bounding_box_target_iou = Variable(bounding_box_target_iou).to(device)
target_iou = bounding_box_target_iou[obj_res].view(-1,5)
################################################################
###### compute loss on cell with no objects ###############
################################################################
# for no object confidence mask
no_obj_confidence = torch.cuda.ByteTensor(no_obj_prediction.size()).fill_(0)
#update the confidence value of the cells with no object for both bboxes
for box in range(num_box):
no_obj_confidence[...,4+box*5] = 1
# then find the prediction and target confidence values
no_obj_conf_prediction = no_obj_prediction[no_obj_confidence]
no_obj_conf_target = no_obj_target[no_obj_confidence]
loss_noobj = F.mse_loss(no_obj_conf_prediction,no_obj_conf_target,reduction="sum")
##########################################################################
################ FOR BOUNDING BOXES COORDNATES #########################
##########################################################################
bounding_box_pred_res = bounding_box_prediction[obj_res].view(-1,5)
bounding_box_target_res = bounding_box_target[obj_res].view(-1,5)
loss_xy = F.mse_loss(bounding_box_pred_res[...,:2],bounding_box_target_res[...,:2], reduction="sum")
##########################################################################
################# FOR BOUNDING BOXES WIDH AND HEIGHT ##################
##########################################################################
loss_wh = F.mse_loss(torch.sqrt(bounding_box_pred_res[...,2:4]),torch.sqrt(bounding_box_target_res[...,2:4]),reduction="sum")
##########################################################################
###################### FOR OBJECT LOSSES #########################
##########################################################################
loss_obj = F.mse_loss(bounding_box_pred_res[...,4],bounding_box_target_res[...,4],reduction="sum")
##########################################################################
################# FOR CLASS LOSS(THOSE WITH OBJECTS) #####################
##########################################################################
prediction_of_class = obj_prediction[...,5*num_box:]
target_of_class = obj_target[...,5*num_box:]
loss_class = F.mse_loss(prediction_of_class,target_of_class,reduction="sum")
return loss_xy, loss_wh, loss_obj, loss_noobj, loss_class
compute_loss = Loss(grid_size, num_boxes, num_classes)