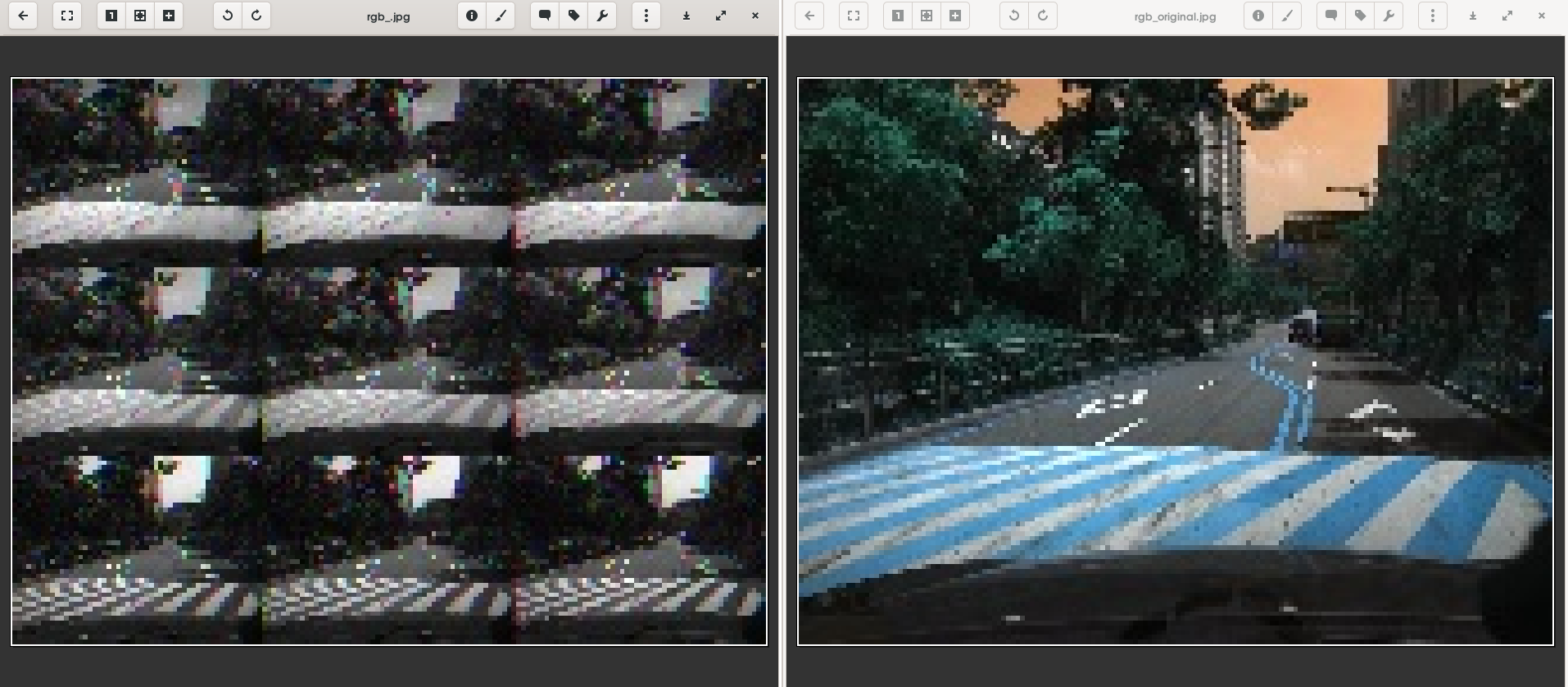
Hello there, I can’t seem to get my input RGB image back corectly after converting it to tensor, it seems that all 9 smaller pictures differ from each other slightly.
Code to reproduce the problem
rgb_img = cv2.resize(rgb_img, dsize = (160,120),interpolation=cv2.INTER_CUBIC)
#(120, 160, 3)
cv2.imwrite("rgb_original.jpg",rgb_img)
rgb_img = np.rollaxis(rgb_img, 2)
#(3, 120, 160)
rgb_img = torch.from_numpy(rgb_img)
rgb_img = rgb_img.type(torch.IntTensor)
rgb_img = rgb_img.to(device="cpu")
rgb_img= rgb_img.unsqueeze(0)# this is just to reproduce the same batch dimension of dataloader
#torch.Size([1, 3, 120, 160])
rgb_img = rgb_img.reshape(rgb_img.shape[2], rgb_img.shape[3], rgb_img.shape[1]).cpu().numpy()
cv2.imwrite("rgb_.jpg",rgb_img)
# #print(rgb_img)
on an another note, is it not a good an idea to train a one class detection model with RGB values or I should follow the good practice of scaling and normalizing my tensors?
Hi,
Glad it worked!
I am not sure about what you mean by scaling and normalization. If you are asking about scaling the values in [0,1] range by dividing RGB values with 255 (pixel value max), then yes, you should use scaling. It will help the model with faster convergence.
I generally don’t use normalization very often as it tends to hurt color consistency in image generation task (I work with image inpainting task). But I have seen some strong arguments for normalization for classification tasks. Most of the normalization values are from ImageNet and work well with most of the images.
I would suggest going through some well-known classification architectures to get some pointers on input processing.
Thanks, I will make sure to train my training abilities x) I will check out the ImageNet norm values and try them out, see if I get better results for my nnet.