Hope you all are havign a fine day.
I have been experimenting with using BERT output embeddings as inputs to a CNN for text classification.
I have set the max number of tokenizers to 256, and batch size is 4. Bert output layer gives a 1d tensor with 768 values.
(Essentially, I am just stacking (1x768) embedding vectors 256 times for each of the 256 tokens in a single sentence that will be used for classification. Each batch has 4 sentences )
Perhaps the following image is going to get the point across:
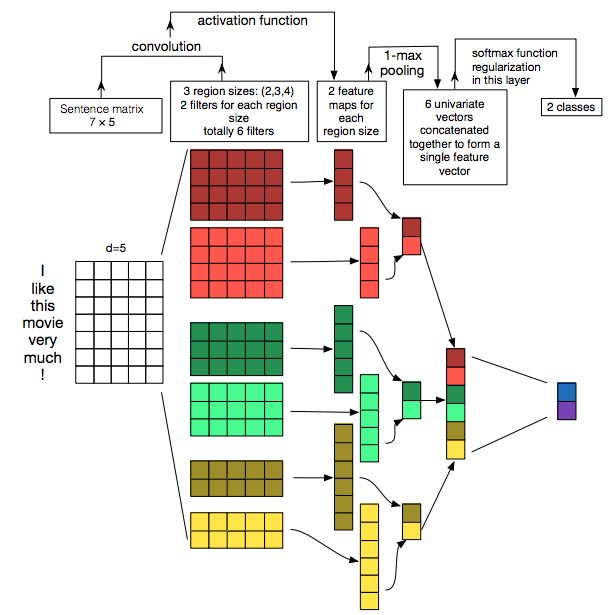
The following are the dimensions of a single batch:
IN
batch = torch.stack([torch.unsqueeze(torch.rand((256,768)),dim=0) for i in range(4)])
OUT
torch.Size([4, 1, 256, 768])
#a single batch with 4 samples, 1 input channel, 256 tokens with 768 rowed embedding tensors
The following is just a snippet of my model and forward method:
class EmbeddingCNN(nn.Module):
def __init__(self):
super(EmbeddingCNN,self).__init__()
self.conv1 = nn.Conv2d(
1,
3,
(5, 768))
self.pool1 = nn.MaxPool2d(kernel_size=(4,))
def forward(self,embedding):
conv1out = self.conv1(embedding).squeeze(3)
print(conv1out.shape)
return conv1out
Instead of convolving with square kernels like in image classification, in the case of text, I am convolving with a 5x768 kernel (which is essentially going from top to bottom if 256 was the height and 768 was the width. The intuition is to apply filters over 5 consecutive words in a sentence) There are 3 output channels in first conv2d layer.
This results in the following dimensions
#conv1out.shape
[1,3,252,1]
Here we come to my question. Why isn’t the length of the first dimension 4 (num of batches)? Why has it reduced to 1? I would assume this convolution assume the following are the meanings of the dimension sizes
1 : ???
3 : Output channel count
4 : "Height" of the convolved layer
5 : "Width" of the convolved layer.
Is this understanding correct? If not, what do the dimensions mean?