Hi, I’m new in Pytorch and I’m using the torchvision.models to practice with semantic segmentation and instance segmentation.
I have used mask R-CNN with backbone ResNet50 FPN ( torchvision.models.detection. maskrcnn_resnet50_fpn) for instance segmentation to find mask of images of car, and everything works well.
I thought that with a different backbone maybe I could reach better result, so I’m trying to change the backbone of Mask R-CNN with MobileNet v2 or ResNext pre-trained, following the instruction on this Pytorch documentation (TorchVision Object Detection Finetuning Tutorial — PyTorch Tutorials 2.2.0+cu121 documentation), but with bad result, producing something like this
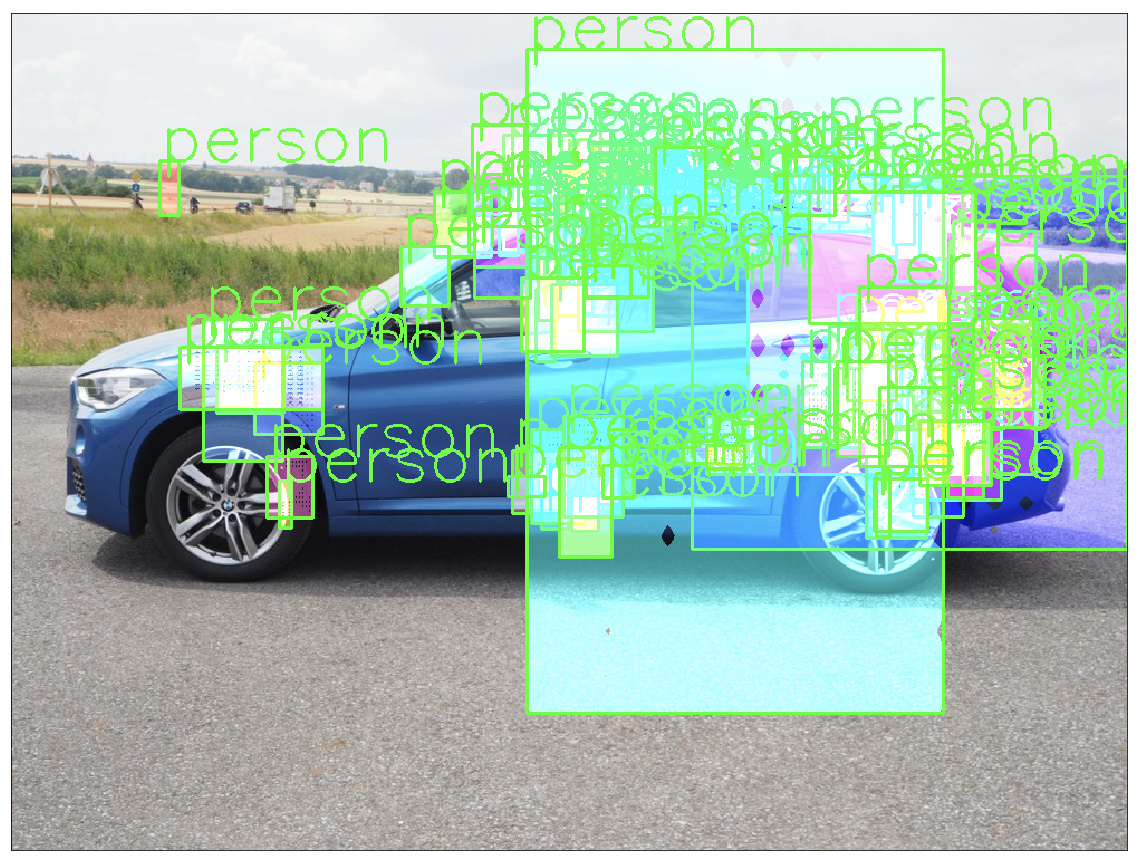
I don’t know if either the models are incompatible (the weight of MobileNet v2/ResNext doesn’t match with mask R-CNN architecture) or I did something wrong in the implementation.
This is the code I have used for instancing the models and backbone:
# import necessary libraries
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
import torchvision
import torch
import numpy as np
import cv2
import random
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=False)
from torchvision.models.detection import MaskRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# load a pre-trained model for classification and return only the features
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# MaskRCNN needs to know the number of output channels in a backbone. For mobilenet_v2, it's 1280, so we need to add it here
backbone.out_channels = 1280
# let's make the RPN generate 5 x 3 anchors per spatial location, with 5 different sizes and 3 different aspect ratios. We have a Tuple[Tuple[int]] because each feature map could potentially have different sizes and aspect ratios
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# let's define what are the feature maps that we will use to perform the region of interest cropping, as well as the size of the crop after rescaling. if your backbone returns a Tensor, featmap_names is expected to be [0]. More generally, the backbone should return an OrderedDict[Tensor], and in featmap_names you can choose which feature maps to use.
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a MaskRCNN model
model = MaskRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
model.eval()
After there are function for color mask, get prediction and instance segmentation …
and this is the code to preprocess and transform the image
img = Image.open('car1.jpg')
from PIL import Image
from torchvision import transforms
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(img)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
img = preprocess(img)
pred = model([img])
Hope someone can help me solving this problem,
thanks in advance!