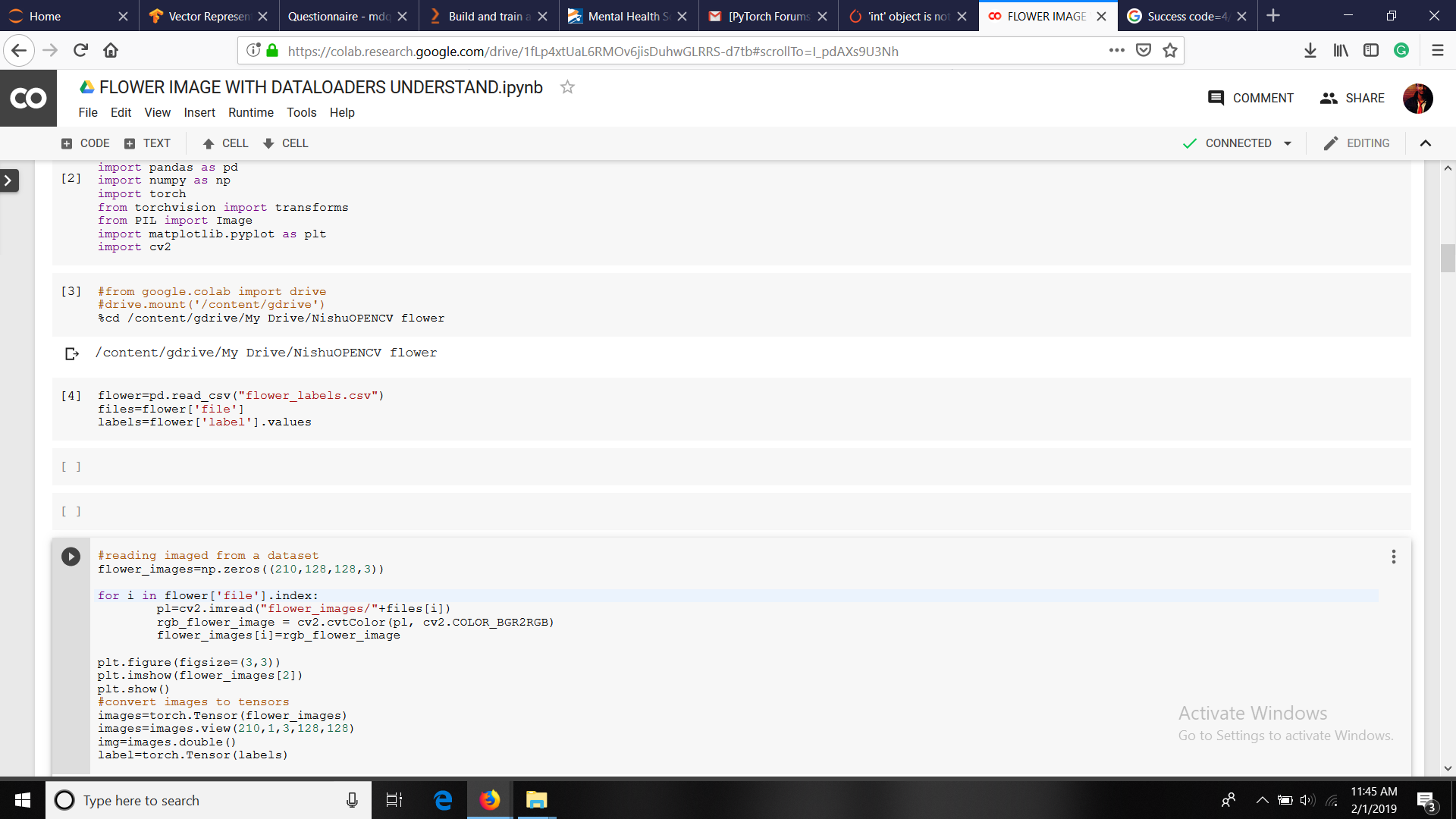
I have converted my images to tensors and use a batch size of 1
print((data.shape))
print(target.shape)
print(target)
outputOf Above code{
torch.Size([1, 3, 128, 128])
()
0
}
#WHY TARGET SIZE IS EMPTY
#USED torch.tensor(label) to convery ndArray to tensor
(TRIED OTHER answers but nothing works)
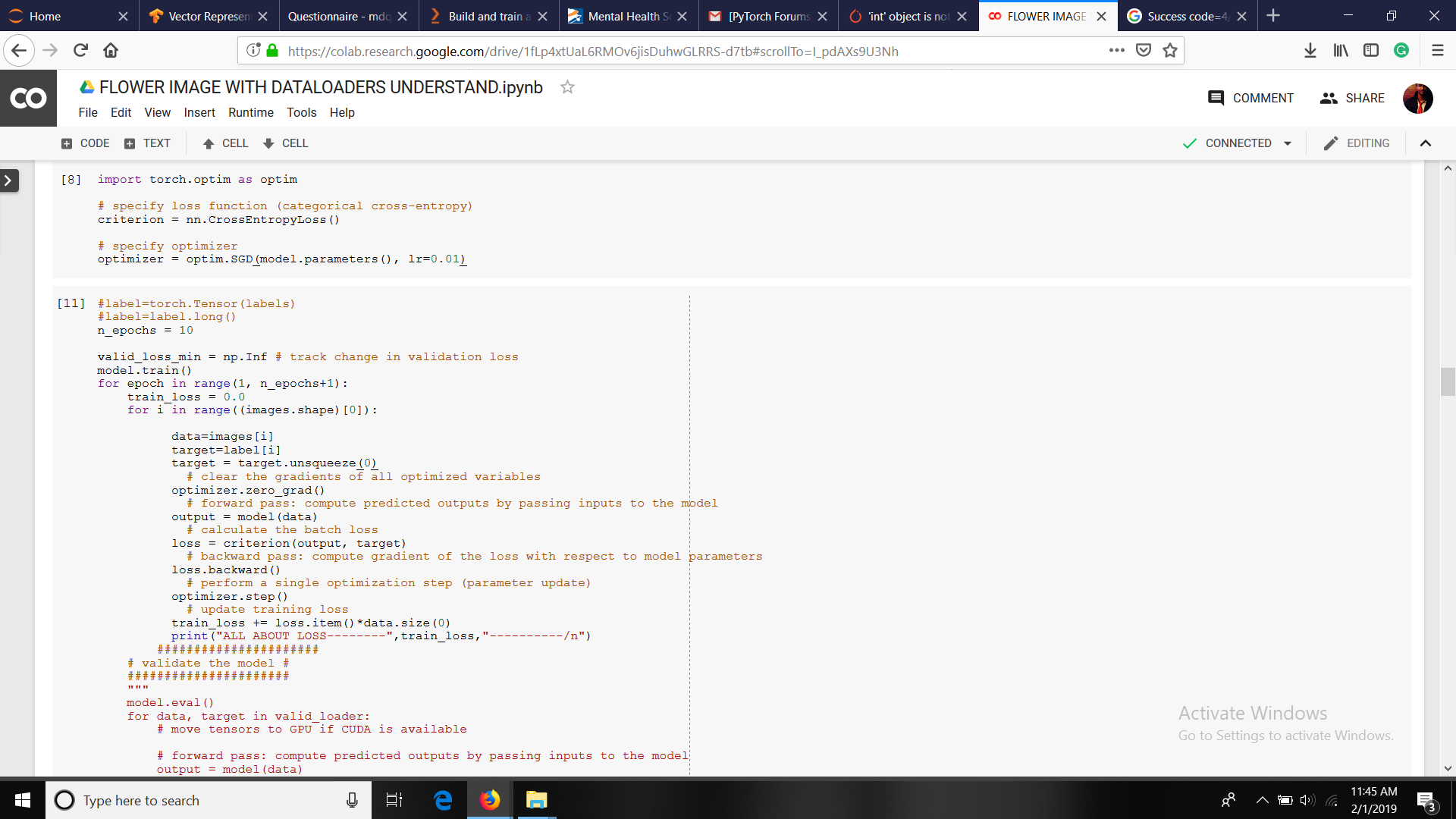
n_epochs = 10
valid_loss_min = np.Inf # track change in validation loss
model.train()
for epoch in range(1, n_epochs+1):
train_loss = 0.0
for i in range((images.shape)[0]):
data=images[i]
target=labels[i]
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
ERROR------
TypeError Traceback (most recent call last)
in ()
25 output = model(data)
26 # calculate the batch loss
—> 27 loss = criterion(output, target)
28 # backward pass: compute gradient of the loss with respect to model parameters
29 loss.backward()
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in call(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
–> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/loss.py in forward(self, input, target)
902 def forward(self, input, target):
903 return F.cross_entropy(input, target, weight=self.weight,
–> 904 ignore_index=self.ignore_index, reduction=self.reduction)
905
906
/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction)
1968 if size_average is not None or reduce is not None:
1969 reduction = _Reduction.legacy_get_string(size_average, reduce)
-> 1970 return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
1971
1972
/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py in nll_loss(input, target, weight, size_average, ignore_index, reduce, reduction)
1784 raise ValueError(‘Expected 2 or more dimensions (got {})’.format(dim))
1785
-> 1786 if input.size(0) != target.size(0):
1787 raise ValueError(‘Expected input batch_size ({}) to match target batch_size ({}).’
1788 .format(input.size(0), target.size(0)))
TypeError: ‘int’ object is not callable
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()*data.size(0)
print(“ALL ABOUT LOSS--------”,train_loss,"----------/n")
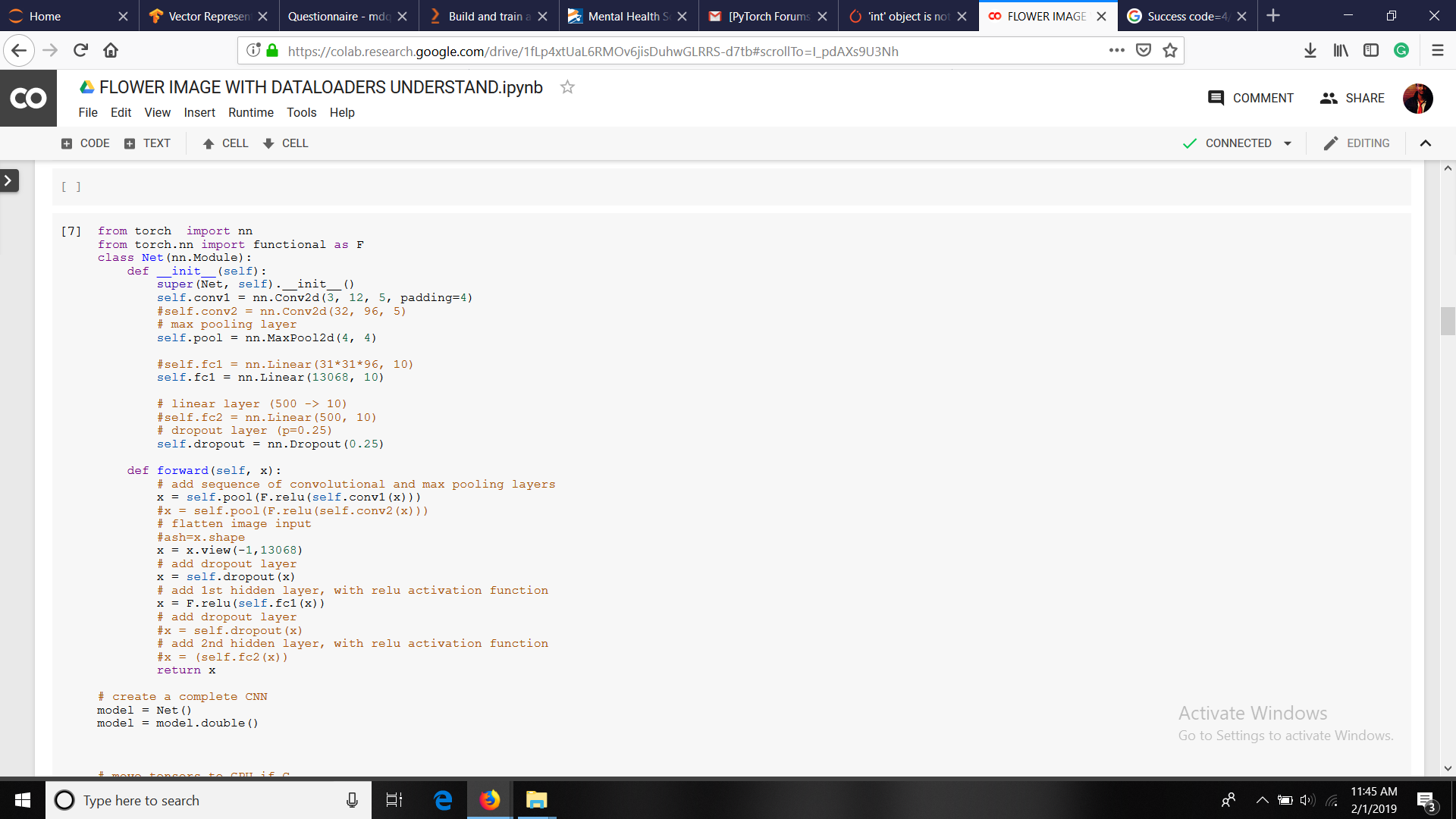
MY MODEL
from torch import nn
from torch.nn import functional as F
class Net(nn.Module):
def init(self):
super(Net, self).init()
self.conv1 = nn.Conv2d(3, 12, 5, padding=4)
#self.conv2 = nn.Conv2d(32, 96, 5)
# max pooling layer
self.pool = nn.MaxPool2d(4, 4)
#self.fc1 = nn.Linear(31*31*96, 10)
self.fc1 = nn.Linear(13068, 10)
# linear layer (500 -> 10)
#self.fc2 = nn.Linear(500, 10)
# dropout layer (p=0.25)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool(F.relu(self.conv1(x)))
#x = self.pool(F.relu(self.conv2(x)))
# flatten image input
#ash=x.shape
x = x.view(-1,13068)
# add dropout layer
x = self.dropout(x)
# add 1st hidden layer, with relu activation function
x = F.relu(self.fc1(x))
# add dropout layer
#x = self.dropout(x)
# add 2nd hidden layer, with relu activation function
#x = (self.fc2(x))
return x
model = Net()
model = model.double()