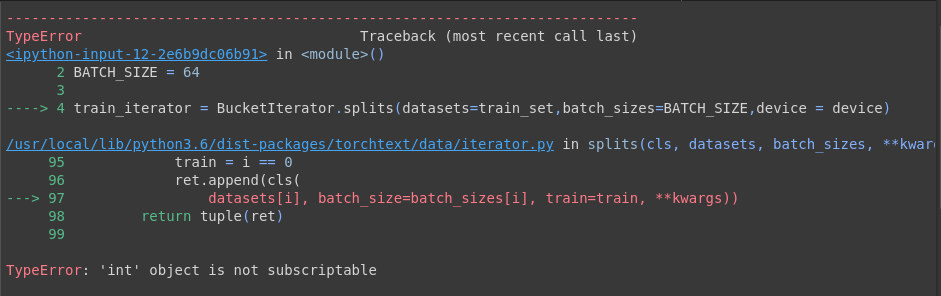
I am getting the following error on using BucketIterator
Which dataset are you using in this case?
Sorry sir for replying late .I was applying it on the aggregator label in WIkiSQL Dataset
Could you copy/paste your code so I can reproduce? You could also open an issue in pytorch/text.
In general, we would like to retire iterator in torchtext. Instead, the new abstraction uses DataLoader in torch.utils.data, like text_classification_dataset
1 Like
Thank you for your concern and sorry again for replying late. It was a problem in the parameters to the BucketIterator . The error has been solved. Thank you sir
Hi @JACOBIN-SCTCS, Could share here how you addressed the problem? Thanks!
Here the datasets contain only one dataset which is train_set. However in my case I had three datasets-train, valid and test. So they are given in a tuple. Thus the batch size should also be given in a tuple(even in the case of the same batch size for all datasets). This way, I solved the problem.
Actually, I know what was the problem. The ‘batch_size’ parameter in BucketIterator automatically changes to ‘batch_sizes’ which is wrong and there is no need to use ‘s’ at the end of the parameter.
1 Like