Hello!
I recently found something interesting when trying to train a Mask RCNN. For those unfamiliar with this type of model, there are 2 inputs:
- A list of images (variable size)
- A list of dictionaries (where each dictionary contains 3 tensors: bounding boxes, segmentation, and class label)
More information regarding input data format can be found here in the documentation
The output is a dictionary of losses (classification loss, segmentation loss, etc). There’s a total of 5 keys/losses. I’m currently summing the losses into one tensor and then calling backward on the summed total loss. (The sum operation will be captured in the tensor graph).
Anyway, here is my problem that I ran into:
Below is some code for a simple training epoch:
for data in enumerate(someDataLoader):
# get the inputs; data is a list of [inputs, labels]
images, targets = data
scenes = images = list(image.to(device) for image in images)
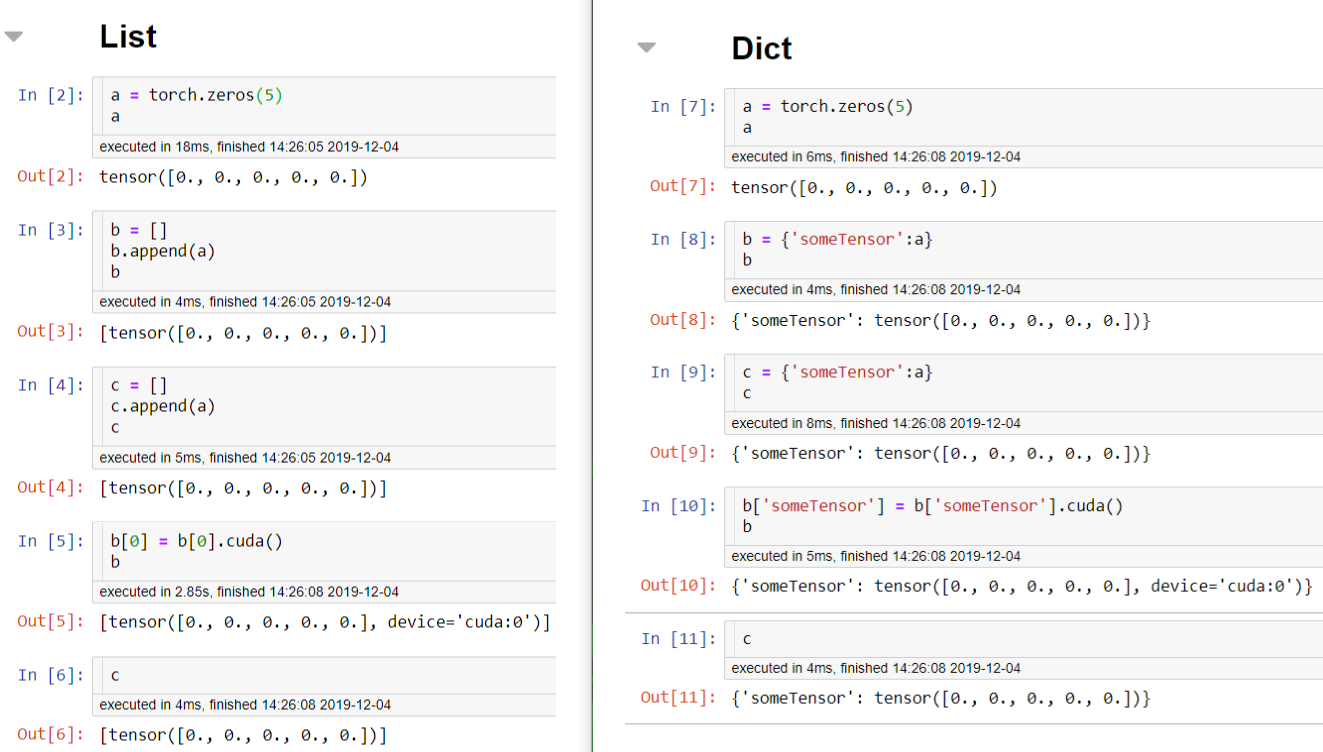
for t in targets:
t['boxes'] = t['boxes'].to(device)
t['labels'] = t['labels'].to(device)
t['masks'] = t['masks'].to(device)
# forward + backward + optimize
loss_dict = maskrcnn_model(scenes, targets)
tot_loss = sum(loss for loss in loss_dict.values())
# zero the parameter gradients
maskrcnn_opt.zero_grad()
tot_loss.backward()
maskrcnn_opt.step()
When running this training loop, I notice that the GPU memory is increasing as more mini-batches are fed. (For example, at the start of training there would be a 3 GB memory usage, after 250 mini-batches, the GPU is at 12 GB memory usage, steadily increasing by 300 MB every 2 seconds). Batch size is fairly small.
To fix this, I looked at some online examples of training a Mask RCNN model. Everything was the same except this portion of the training loop:
for t in targets:
t['boxes'] = t['boxes'].to(device)
t['labels'] = t['labels'].to(device)
t['masks'] = t['masks'].to(device)
Instead of doing it the way I did above, they used a list comprehension and basically made a new dictionary for each target, and saved into a separate list. An example of that would be either of the following code snippets below (I find the top code snippet to be more read-able, but they both do the same thing).
newTargs = []
for t in targets:
x = {}
x['boxes'] = t['boxes'].to(device)
x['labels'] = t['labels'].to(device)
x['masks'] = t['masks'].to(device)
newTargs.append(x)
newTargs = [{k: v.to(device) for k, v in t.items()} for t in targets]
After making a new list of dictionaries, newTargs is then used in the forward pass of the model, rather than targets.
E.g. loss_dict = maskrcnn_model(images, newTargs).
This small change in code maintains GPU memory of 3 GB throughout the training epoch.
Any thoughts on why?
Thanks,
Epoching