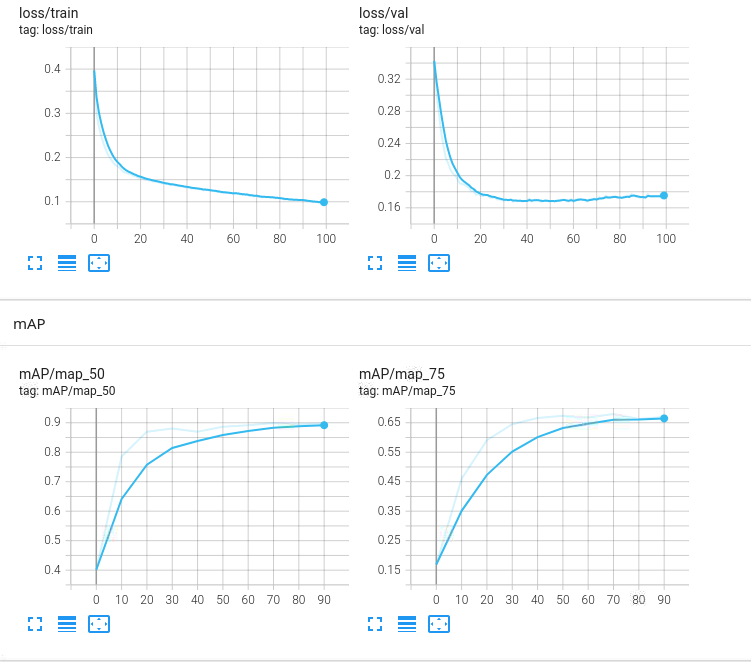
Training loss is descending, but test loss and mAP don’t… what will be the most common approach? Continue training or stop.
What you should do?
Thanks for comment
Training loss is descending, but test loss and mAP don’t… what will be the most common approach? Continue training or stop.
What you should do?
Thanks for comment
Hi naxto!
To my eye, it looks as if your training has started overfitting your training
set.
I say this because your validation loss has started going up (albeit modestly)
while your training loss is continuing to go down. The idea is that your
network is continuing to learn – your training loss is going down – but it’s
learning details specific to your training set that aren’t actually relevant to
your real problem (as represented by your validation set).
All else being the same, you should stop training when your network starts
overfitting.
If you have the resources (and patience) you could double-check this by
rerunning your training from scratch starting with a different random
initialization of your network (and also a different random split between
your training and validation datasets). I expect that if you do so you will
see the same general structure – validation loss starts going up, while
the training loss continues to decrease – although the exact numbers will
differ.
If you care, some things you can try in order to reduce / postpone overfitting:
Weight decay and dropout can reduce overfitting.
If you still need to achieve better validation / test performance, the best
way to reduce overfitting is to train with a larger training set – if you have,
or can acquire, more training data. If you don’t have more data, you can
try data augmentation to get some of the benefits of more actual data.
Best.
K. Frank
My suggestion is to take a word from Karpathy’s advice A Recipe for Training Neural Networks
Overfit, regularize and then Tune ![]() I think the blog will explain better than anyone else.
I think the blog will explain better than anyone else.
@KFrank Ok, got it!!
Even test loss increase very very small, as train loss is going down means that’s is only learning features that are exclusive from train set, as when try to use those on test set, loss increase so whats learning is not useful
@oke-aditya thanks for that link is super helpful!!
So or i get the model at epoch 30 or try to improve training… i will try to improve ![]()
After reading KFrank comment and that karpathy blog im going to:
Thanks to both, i’m learning a lot here!!