Hello, I am using a resnet18 to do some Finetuning classification on a dataset of dogs breeds and I’m struggling to get good results. This is how the losses and accuracies look like.
What does it mean that the validation loss is smaller all the time than the train loss?. Is 80% a reasonable accuracy for this kind of problem?.
Any tips on how to approach this kind of classification would very much be appreciated! Thanks in advance. 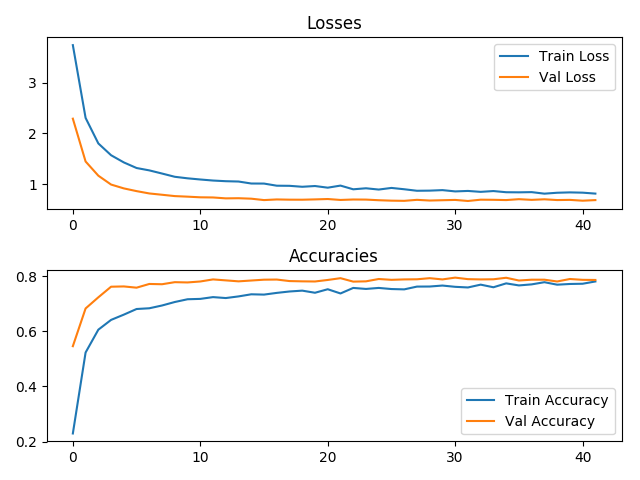
Your results depends on many factors; train size, test size, train batch size, test batch size, learning rate + optimizer and how accurately you compute the metrics. Might you include your full code, that would make it easier to advice you.
1 Like
Thanks for your reply here its the code:
The model
resnet_model = models.resnet18(pretrained=True)
for param in resnet_model.parameters():
param.requires_grad = False
num_ftrs = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(num_ftrs, len(classes))
resnet_model = resnet_model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(resnet_model.fc.parameters(), lr=1e-3, weight_decay=0)
Data
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
}
images = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(images[x], batch_size=128,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
Training
def train():
resnet_model.train(True)
torch.set_grad_enabled(True)
running_loss = 0.0
running_corrects = 0
for data in dataloaders['train']:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = resnet_model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_corrects += torch.sum(preds == labels).item()
epoch_loss = running_loss / len(dataloaders['train'])
epochs_acc = running_corrects / dataset_sizes['train']
return epoch_loss, epochs_acc
Validation
def evaluate():
resnet_model.train(False)
running_loss = 0
running_corrects = 0
for data in dataloaders['val']:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
outputs = resnet_model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
running_loss += loss.item()
running_corrects += torch.sum(preds == labels).item()
epoch_loss = running_loss / len(dataloaders['val'])
epochs_acc = running_corrects / dataset_sizes['val']
return epoch_loss, epochs_acc
Main Loop
while True:
epoch_start_time = time.time()
train_loss, train_acc = train()
train_losses.append(train_loss)
train_accuracies.append(train_acc)
print('-' * 73)
print('| End of epoch: {:3d} | Time: {:6.2f}s | Train loss: {:.2f} | Train acc: {:.2f}|'
.format(epoch, (time.time() - epoch_start_time), train_loss, train_acc))
val_loss, val_acc = evaluate()
val_losses.append(val_loss)
val_accuracies.append(val_acc)
print('-' * 73)
print('| End of epoch: {:3d} | Time: {:6.2f}s | Valid loss: {:.2f} | Valid acc: {:.2f}|'
.format(epoch, (time.time() - epoch_start_time), val_loss, val_acc))
if val_loss < best_val_loss:
with open('resnet_model.pt', 'wb') as f:
torch.save(resnet_model, f)
best_val_loss = val_loss
bad_epochs = 0
else:
bad_epochs += 1
if bad_epochs == 10:
break
epoch += 1
I have taken a look at it, there are a few problems with it. I suggest the following solutions
First add
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
just before ToTensor in both the train and test transforms.
Step2.
You don’t need to shuffle the test set, I suggest you should just load the test and train sets without using the loops over array, that is even cleaner.
Step3:
Here is where the real problem is.
The way you compute the average loss and accuracy.
len(data_loader) would return number of batches, hence you are dividing the total metrics by the number of batches instead of number of examples.
Here is what you need to do, define
num_images = 0
At each batch iteration do
num_images += inputs.size(0)
Note that inputs.size(0) would give the total images in each batch.
Finally
epoch_loss = running_loss/num_images
epoch_acc = running_acc/num_images
That would give you accurate metrics
Do same in the evaluate function
Also, torch.save accepts filenames too, you really shouldn’t bother using open
2 Likes
what about running_loss/len(dataloader['val'].dataset) ? Its has the same effect, but more efficient in runtime.
1 Like
That’s cool, cuts out the extra computation.
However, the batch by batch implementation is useful if logging the metrics after N batches rather than at the end of the epoch. You can simply divide the running loss by the num_images at any number of iterations to get current average.
However, if averaging is done only at the end of each epoch, your code is just okay.
I am confused about a couple things:
For each batch you get one loss value, so why should I average over all the samples instead of over the batches?
Wouldn’t that give me a very small loss value? Since I am adding 64 loss values (64 batches) and dividing by all the images (8000 more or less)?
Also how can I decide which values to normalize with is 0.5 a good choice by default?
Although the loss is one value, it represents the sum of losses over all examples in the batch, hence the effective total loss is the sum of losses over all N images rather than sum over M batches. The normalization values is mean and std values, it differs for various datasets, however, 0.5 is generally a good default to use for any generic dataset.
Thanks a lot for your help. I was looking at the Transfer Learning Tutorial and I found the normalization it’s done with:
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
It seems that resnet18 was trained using this normalization, so I am using that one and the results seem to improve somewhat.
When it comes to the loss part, he calculates it like this:
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
With phase being either ‘train’ or ‘val’ and dataset_sizes[phase] being the all of the examples used in training or validation. So yes he does divide by all of the samples but before accumulating the loss value he multiplies by all the examples in one batch.
Any insight on why this is done this way?
If I divide the loss value by the totality of examples like you suggest, I get really small loss values, like 0.003 and 0.002.
Help.
There is a flaw in my earlier explanation
Running loss should be
running_loss += loss.item() * inputs.size(0)
Not
running_loss += loss.item()
Contrary to what I earlier said, the loss returned is an average over all examples in a batch, given this, you could simply divide the running loss by the number of batches, however since the final batch is often not the same size with others, your results would be inaccurate, hence, the solution is to reverse the average by multiplying the loss in a batch by the total number of images in the batch, this gives unaveraged sum of losses over all examples, when you divide the running loss by the total number of images ,you get accurate loss metrics.
The line
dataset_sizes[phase]
Uses the approach suggested by @roaffix
It returns the number of Images in the dataset.
2 Likes
Great! Thank a lot for your help. Now that we know that I am calculating the metrics correctly. What does it mean that the validation loss is always smaller than the train loss, this is certainly not normal IMO and I don’t now how to deal with it. Any tips?
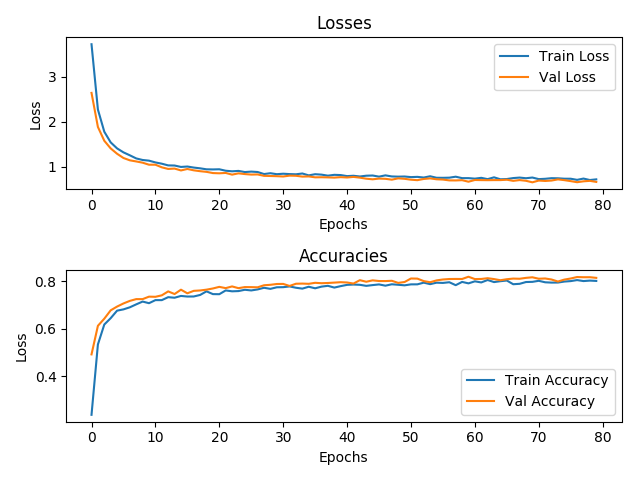
You are welcome. It is possible for your train loss to be higher than your test loss. Often this occurs early in training. This might be due to the total number of test images being substantially smaller than the train set. How many images is in your train and test sets respectively?
I use 8221 images for training and about 25% of that (2001) for validation
This issue often occurs when using regularization like Dropout, i.e. Dropout makes your models “smaller” (lowers the capacity), thus your training loss might be higher than your validation loss.
However, since you are using a resnet, this won’t be the reason.
Another reason is the intrinsic variance of the dataset as @johnolafenwa said. If your dataset is quite small, the inner variance of the training dataset is just higher than in the validation set.
The most likely reason for me is, because you are collecting your training loss during the whole epoch while you are training the model. So at the beginning of each epoch the loss will be higher, at the end of an epoch lower. Since you are just summing the losses and dividing by the total number of images, your estimate might be a bit biased.
3 Likes
Thanks a lot for your reply. Is there any way to reduce this bias or do I just have to accept it and move on. Is there any better way to calculate and/or plot the losses?
Well, you could calculate the resubstitution error (using the training data) after each epoch with model.eval(), but to be honest, I would just stick to this estimate.
2 Likes
In fact the loss is average rather than the sum of losses unless you indicate reduction = 'sum' in the loss function.
Hi Diego, what was the first value that you use for ‘best_val_loss’ ? Could you explain a little bit that part? I am interested to save the best model. Thanks
Your validation accuracy is consistently higher than train accuracy. Strongly suggest to check this, it shouldn’t be happening.