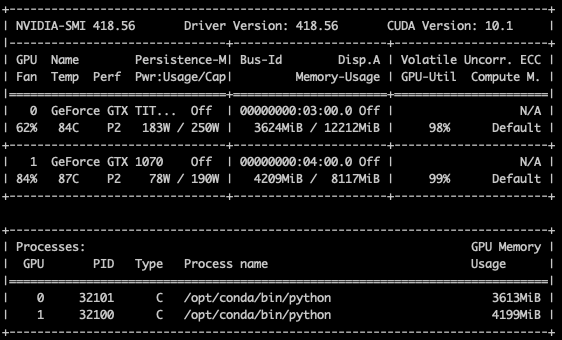
Is it expected for nn.parallel.DistributedDataParallel in a 1GPU:1Process setup to use a little extra memory on one of the GPUs? The use isn’t exorbitant ( 3614 MiB vs. 4189 MiB). If so, what is this extra memory used for? Is it the all_reduce call on the gradients? If not what would this be attributed to?
1 Gpu per 1 process spun up with: mp.spawn(run, nprocs=args.num_replicas, args=(args.num_replicas,))
Entire module wrapped with nn.parallel.DistributedDataParallel
loss function is a member of above module.
pytorch 1.4
Multiprocessing init created via:
def handle_multiprocessing_logic(rank, num_replicas):
"""Sets the appropriate flags for multi-process jobs."""
args.gpu = rank # Set the GPU device to use
if num_replicas > 1:
torch.distributed.init_process_group(
backend='nccl', init_method='env://',
world_size=args.num_replicas, rank=rank
)
# Update batch size appropriately
args.batch_size = args.batch_size // num_replicas
# Set the cuda device
torch.cuda.set_device(rank)
print("Replica {} / {} using GPU: {}".format(
rank + 1, num_replicas, torch.cuda.get_device_name(rank)))
Yes, this is expected currently, because DDP creates buckets to consolidate gradient communication. Checkout this and this. We could potentially mitigate this problem by setting param.grad to point to different offsets in the bucket so that we don’t need two copies of grads.
Thanks for the response; just to clarify: you mean it is expected that 1 of the GPUs in say a 2 GPU (single-process-single-gpu) DDP setup will use more memory because of bucketing? Wouldn’t the buckets be of the same size on both devices?
The general problem of more memory makes sense in the current way things are setup (from your src links), let me see if I can come up with a minimum viable example for this effect (more mem on one of the GPUs).
Is the DDP process the only process using that GPU? The extra size ~500MB looks like an extra cuda context. Does this behavior still persist if you set CUDA_VISIBLE_DEVICES env var properly (instead of using torch.cuda.set_device(rank)) before launching each process?
I don’t set CUDA_VISIBLE_DEVICES but I do call torch.cuda.set_device(rank) before instantiating the model / optimizers, etc (see function in initial post).
Edit: not sure how I would be able to set the ENV var when using mp.spawn such that it doesn’t apply to both processes.
Using pytotch 1.5, setting CUDA_VISIBLE_DEVICES appropriately per process, doing any CUDA related stuff before the ENV var is set and changing the DDP constructor with:
device_ids=[0], # set w/cuda environ var
output_device=0, # set w/cuda environ var
It might be relevant to this post. If CUDA_VISIBLE_DEVICES is not set to one device per process, and the application program calls clear_cache somewhere without a device context, it could try to initialize the CUDA context on device 0.