Is it ok to use dist.barrier() in the forward/backward of a custom pytorch torch.autograd.Fucntion?
I have a custom torch.autograd.Function looks like this (adding dist.barrier() because I am debuggling my code with other errors):

I am encountering randomly training hangs where the error look like:
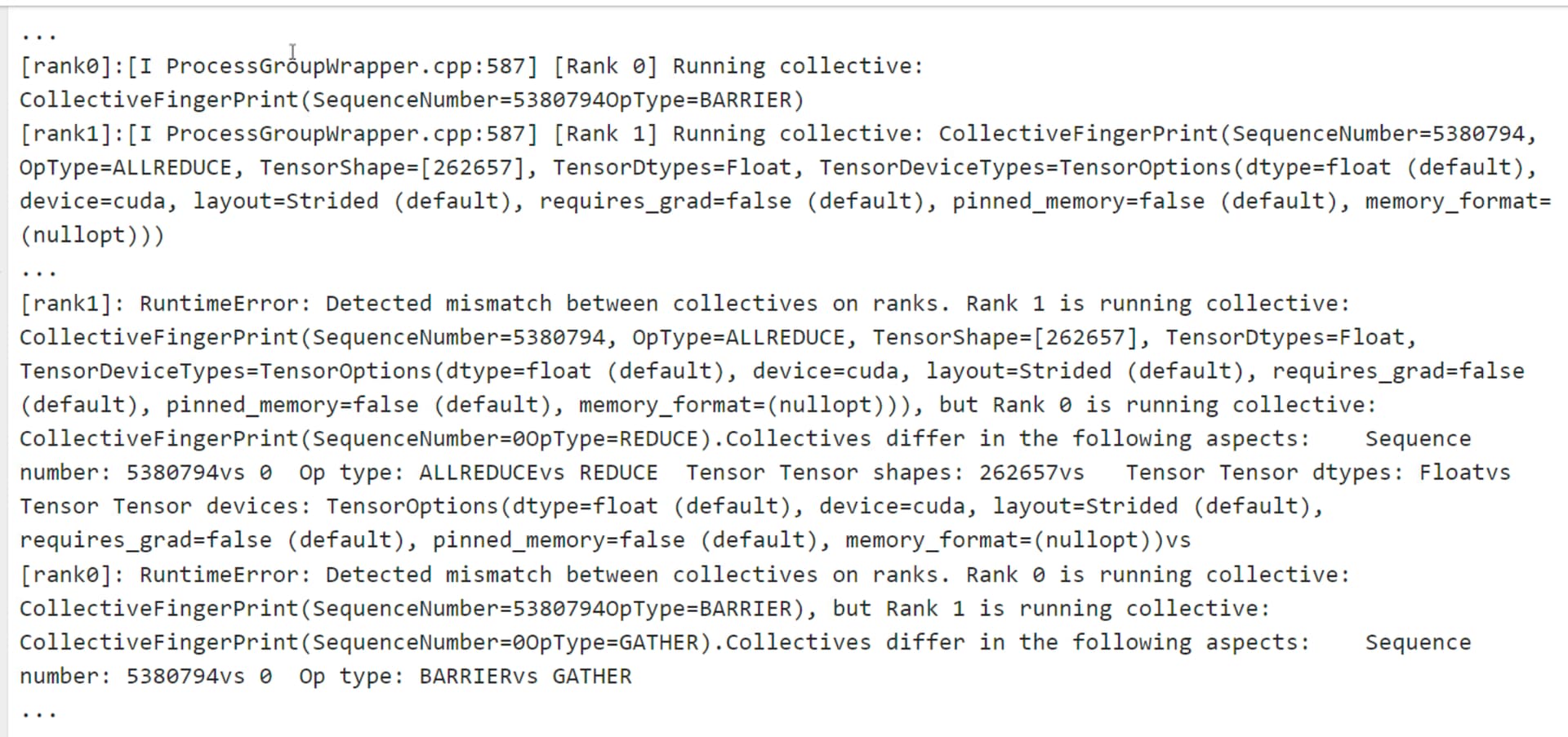
It looks like rank0 is doing dist.barrier() written by me in the backward function above, while rank1 is doing all_reduce of some gradient by ddp itself.
This error occurs randomly (5 in 200 same experiments with different seeds).
Is it possible that in rank0 and rank1, ddp all_reduce gradients asyncly? (so that rank0 enters my dist.barrier(), and rank1’s ddp is already starting to try to sync some gradients between gpus?)
p.s. some context:
- env: python=3.9.7, pytorch=2.3.0+cu121. Some flags added for showing the above debuggling msgs: TORCH_CPP_LOG_LEVEL=INFO TORCH_DISTRIBUTED_DEBUG=DETAIL TORCH_SHOW_CPP_STACKTRACES=1
- I am using a lot of custom torch.autograd.Function to sync data and gradients between gpus in my training code.
- Only rank0 is doing validation every several training iterations (rank1 waits and do nothing, I also add a dist.barrier there.)
Thanks!