Does it make any discernible difference to a model whether activation function modules are reused within a neural network model?
Specifically, is it expected that training results differ depending on whether you reuse such modules or not?
Example model without reusing ReLU’s:
class NormalModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = conv_block(3, 64)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = conv_block(64, 1)
def conv_block(self, chin, chout):
return nn.Sequential(
nn.Conv2d(in_channels=chin, out_channels=chout, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(chout),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
return x
Note above that two separate nn.ReLU objects are instantiated, each stored only once in the NormalModel class, and each applied to data only once in the forward pass.
Example model with reusing ReLU’s:
class ReusedModel(nn.Module):
def __init__(self):
super().__init__()
self.act_func = nn.ReLU(inplace=True)
self.conv1 = conv_block(3, 64)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = conv_block(64, 1)
def conv_block(self, chin, chout):
return nn.Sequential(
nn.Conv2d(in_channels=chin, out_channels=chout, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(chout),
self.act_func,
)
def forward(self, x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
return x
Note above that the single instantiated nn.ReLU object is stored three times within the ReusedModel class, and applied twice to different data (of different sizes) during the forward pass. The naive rationale of why this shouldn’t matter is that nn.ReLU internally just calls F.relu() anyway, and doesn’t store anything else in the class, so how can it make a difference?
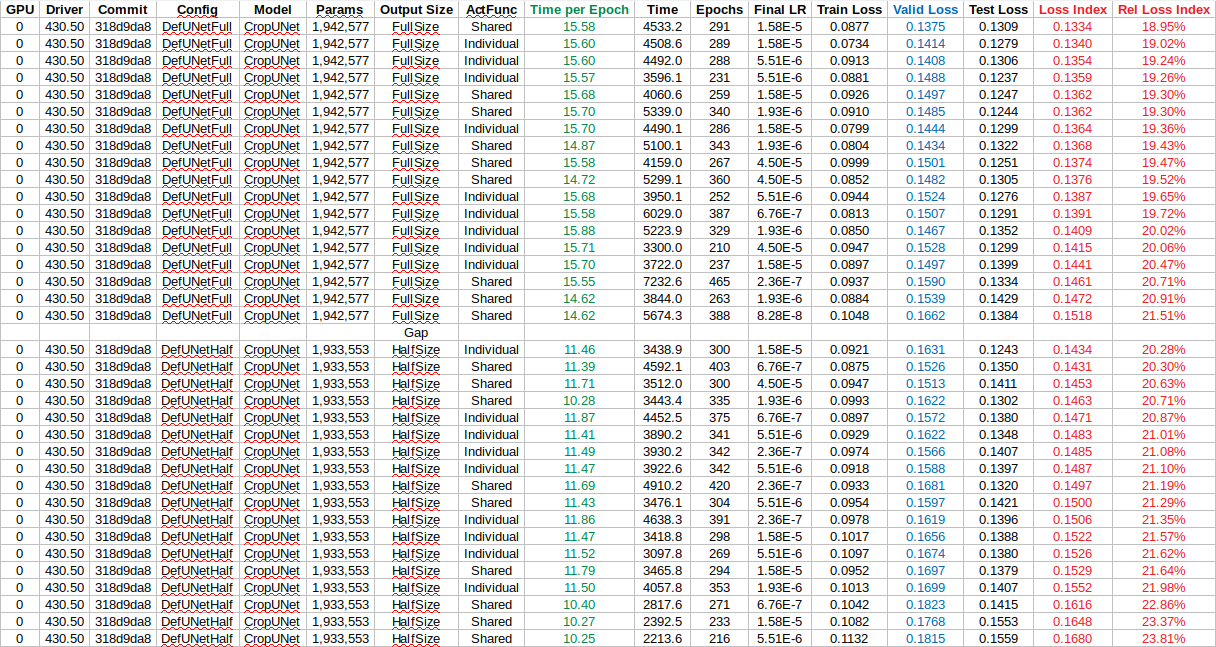
With a more complicated model than the example one above, I repeatably obtain worse training performance if I reuse the ReLUs, as compared to doing things the ‘normal’ way. I have tested it many many times now but it keeps coming out the same. Why could this be?
PyTorch:
Version = 1.4.0a0+7f73f1d
Git commit = 7f73f1d591afba823daa4a99a939217fb54d7688
Compiled with CUDA version = 10.1
Compiled with cuDNN version = 7.6.5
Compiled with NCCL version = 2.4.8
OpenMP available = True
MKL available = True
MKL-DNN available = True