Hi all,
I have thousands of images that look like below:

The different shapes are the growth we are interested in detecting. Every image has unique shapes in it and some images have hundreds of these objects we are interested in.
Another example is:

We want to extract the shapes only and extract the background.
Since they are all different shapes, it is not possible to train a single model as we have 1 image per shape.
One solution I tried was to train a segmentation model using the input image that has been part labelled and then once it learns the shape, the same image can be used to identify the rest of the shapes.
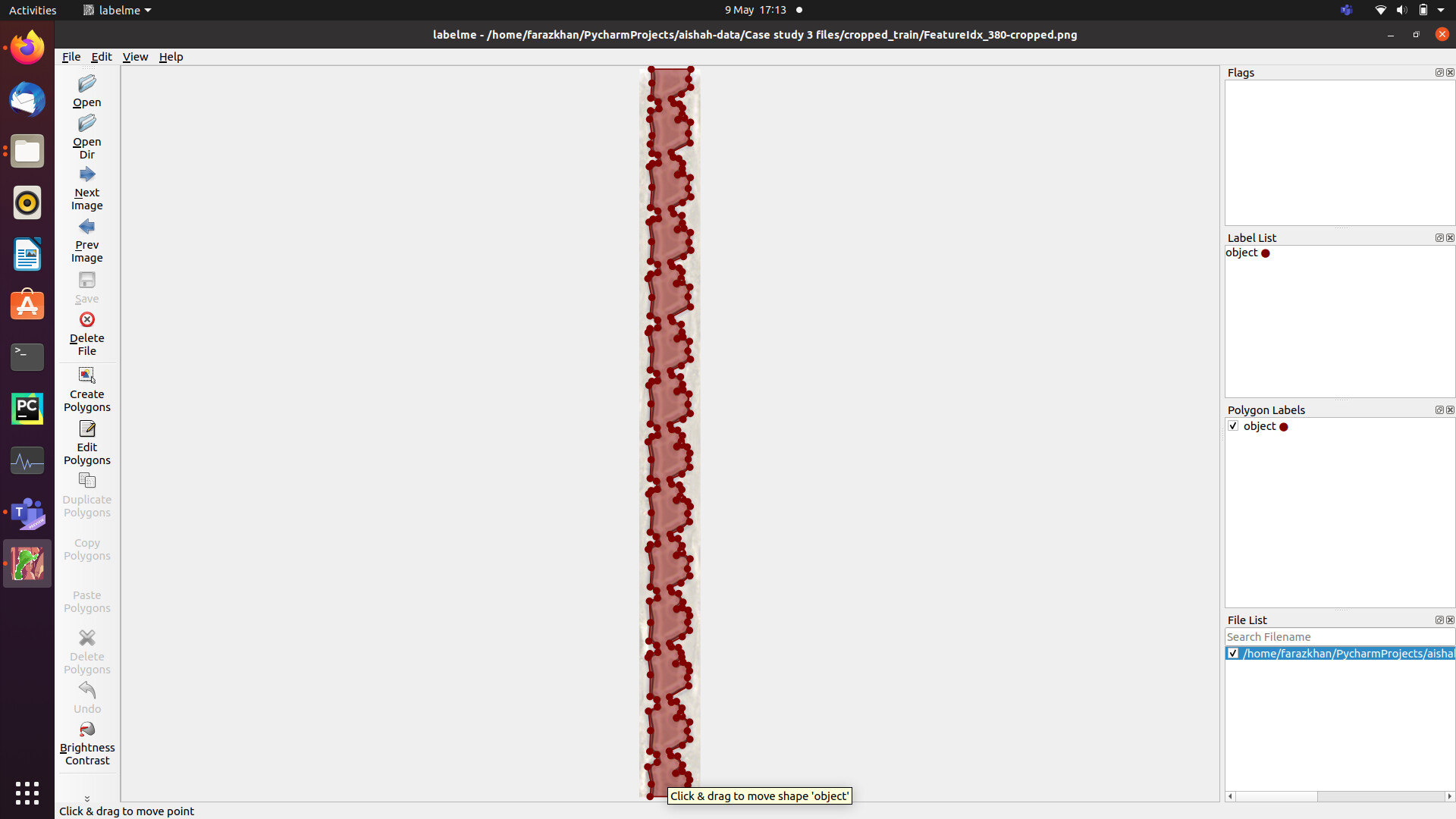
For example, in labelMe I created a label file for one of the shapes:

Then trained a model using this image.
The assumption was that after training, the model would be able to identify the rest of the shapes in the image. But what actually happens is that it only identifies the training data. The same mask that was used to train it.
This does make sense as the model overfits to the input data, and when the test image is the same training image.
So my question is, given the problem I have, is it even possible to train a model like this? Learn from the input image and then use that to identify the remaining objects in the same image?
Or would I have to look into conventional computer vision approaches for this?
Thank you