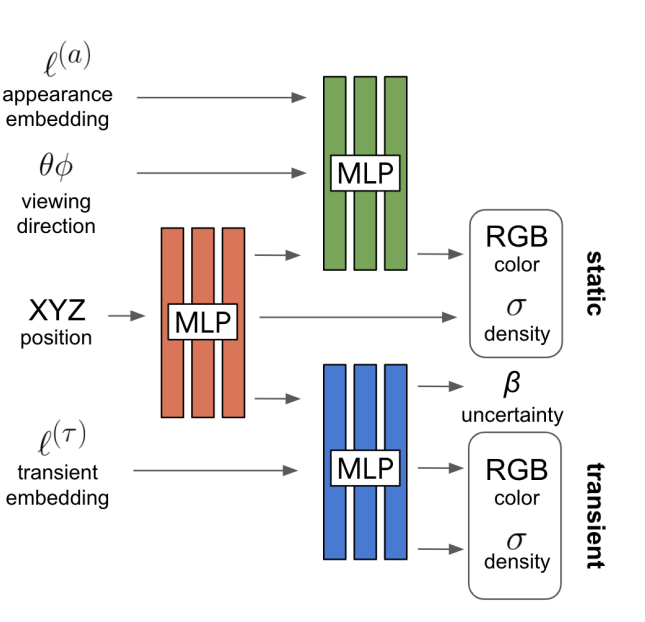
This is a figure from Nerf in the wild. (You may not need to know what it is exactly)
In brief, “Static” RGB and “Transient” RGB value will be compared to the ground truth value and loss for each is calculated.
What I want to do is, for instance, transient embedding is updated only based on loss from static value, not the transient one. So, I write the code like below.
static_loss.backward(retain_graph=True)
static_grad = transient_embedding.grad
transient_loss.backward()
transient_embedding.grad = static_grad
optimizer.step()
If the code serves right, all the other parameters must be updated based on both losses, and transient embedding is updated based only on static loss. The result is not quite satisfactory, but I want to know whether the bad result comes out because the approach above is not a good idea in itself (or just wrong)