When I worked with Tensorflow, I used to define a model’s forward pass and other customizations under its def __call__(self, x) function. If I want to implement the same thing in PyTorch, should I do it in def forward(self,x) instead?
It is just a naming convention. Why do you want to define call(x) again inside the forward function? It isn’t needed, just use the forward function to get the outputs for the input data. Check this tutorial https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
__call__ is already defined in nn.Module, will register all hooks and call your forward. That’s also the reason to call the module directly (output = model(data)) instead of model.forward(data).
The problem with using __call__ is that it is impossible for the IDE to know that __call__ calls forward. Therefore, the IDE cannot help you with passing the correct arguments to forward for example.
This has created major unknown bugs in my code before. For example, I accidentally passed the wrong tensor to forward. If the IDE knew the correct arguments to forward then this issue would have been caught.
wondering if you found a way around this issue?
currently, i am using .forward everywhere in my code until i’m ready to train. then i’ll bulk find and replace .forward for call
@Rishi_Malhotra that’s an interesting solution.
I haven’t done this before, but I guess you could override the __call__ method to call the parent __call__ method and specify the arguments in the overridden one. Example:
class Foo(nn.Module):
def forward(self, bar: torch.Tensor):
print(bar.shape)
def __call__(self, bar: torch.Tensor):
super().__call__(bar=bar)
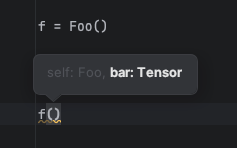
For annotating __call__ to be the same as forward. You can see my workaround on a Github issue here
https://github.com/pytorch/pytorch/issues/74746#issuecomment-2574443618