To check whether you have CUDA access inside your code, you can use:
>>> print(torch.cuda.is_available())
True
If it return false, I highly recommend to check the CUDA version you have installed and make sure that you have installed corresponding PyTorch version.
Check CUDA version:
>>> nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2015 NVIDIA Corporation
Built on Tue_Aug_11_14:27:32_CDT_2015
Cuda compilation tools, release 7.5, V7.5.17
Install Pytorch 1.0 for CUDA 8.0 and above, follow this link $ conda install pytorch torchvision cuda80 -c pytorch
Install previson verison of Pytorch for CUDA 9.0 and below, follow this link $ conda install pytorch=0.4.1 cuda80 -c pytorch
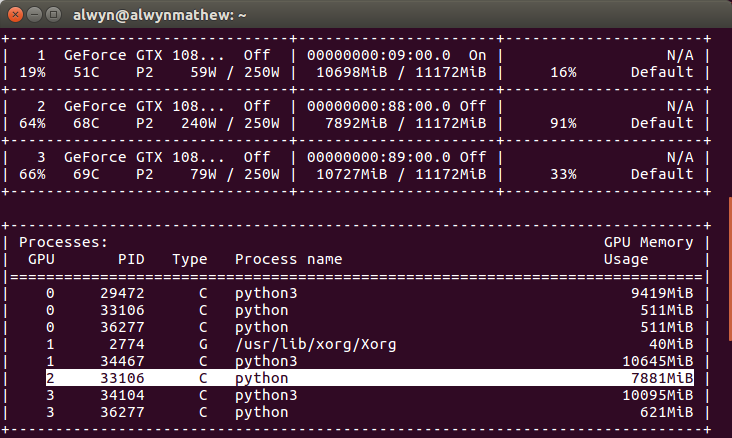
Not necessarily. It looks like the GPU utilization is at 38%.
I’ve seen some weird behavior in nvidia-smi: sometimes showing all processes, sometimes not showing any processes at all on certain servers.
Could you use @alwynmathew’s suggestions to check if CUDA is available?
If so, check if your data (, model parameters, target) is on the GPU using print(tensor.device).
CUDA is available, and doing a torch computation with GPU works
I don’t think that is 38% GPU utilization, because if you look at an earlier column it says 512/11441 MiB are used, which is only around 5% utilization…
The memory usage does not correspond to the GPU utilization which gives as far as I know the percentage of the time a kernel was executed in the last time frame.
No, I think the drivers should be installed directly on the machine and not in the docker file. At least that was my last workflow.