Hello everyone. I’m doing a BC task on DeepFake recognition.
I have the following CSV for the features of a video as follow:
===================================================
IDX ldmk1_x ldmk2_x ldmk3_x ldmk4_x ldmk5_x ... ldmk64_y ldmk65_y ldmk66_y ldmk67_y ldmk68_y
0 199.000000 199.666667 200.666667 201.833333 205.666667 ... 140.166667 140.666667 140.333333 140.833333 140.000000
1 198.166667 198.500000 199.833333 201.500000 205.833333 ... 143.833333 144.666667 144.500000 145.166667 144.333333
2 197.833333 198.166667 199.666667 202.000000 206.000000 ... 147.000000 147.833333 147.333333 148.000000 147.333333
3 197.000000 197.666667 199.000000 200.833333 204.833333 ... 146.333333 147.500000 147.333333 147.666667 147.000000
4 190.000000 190.333333 191.500000 193.500000 196.833333 ... 147.166667 148.000000 148.166667 148.500000 148.166667
.. ... ... ... ... ... ... ... ... ... ... ...
59 258.666667 258.666667 259.166667 260.666667 262.666667 ... 69.166667 69.833333 70.833333 71.333333 71.166667
60 255.666667 256.333333 257.333333 259.333333 262.500000 ... 67.333333 67.000000 67.833333 67.833333 68.500000
61 266.500000 266.666667 267.500000 268.500000 270.833333 ... 63.000000 64.500000 65.000000 65.000000 65.000000
62 295.333333 294.500000 294.000000 294.000000 295.166667 ... 68.666667 69.500000 69.333333 69.166667 68.666667
63 277.000000 276.500000 276.500000 277.166667 279.166667 ... 68.333333 69.000000 70.833333 71.000000 70.833333
Which is composed by 64 rows and 136 columns, for now (I’m still adding a lot of rows).
Each 16 rows denote a video (made of 16 frames) and the corresponding label (0/1) where 0 is denoted as Fake and 1 is denoted as Real.
Each column corresponds to an anchor point on a person face and how it is evolving during the various 16 frames.
The labels are located into another CSV:
IDX Label
0 0
16 0
32 1
48 1
It means that the first 16 rows of the features I have label 0.
The rows from 16 to 32 have label 0.
The rows from 32 to 48 have label 1.
The rows from 48 to 64 have label 1.
Now, with this being said I instantiated my model as follows:
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
# 24 Features
self.flatten = nn.Flatten()
self.relu = nn.ReLU()
self.fc1 = nn.Linear(2176, 1088, dtype=torch.float64, device=device)
self.fc2 = nn.Linear(1088, 512, dtype=torch.float64, device=device)
self.fc3 = nn.Linear(512, 256, dtype=torch.float64, device=device)
self.fc4 = nn.Linear(256, 128, dtype=torch.float64, device=device)
self.fc5 = nn.Linear(128, 1, dtype=torch.float64, device=device)
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.relu(self.fc3(x))
x = self.relu(self.fc4(x))
x = self.fc5(x)
return x.reshape(-1)
Where 2176 parameter in the self.fc1 layer is given by the Flatten output of self.flatten(x)
Now, the tricky part, the dataset. Knowing that my DataFrame is composed as I explained above, I did the following Dataset class:
class DeepFakeDataset(Dataset):
def __init__(self, X, y, batch_sz):
self.X = X
self.y = y
self.count = 0
self.b = batch_sz
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
if (idx % self.b == 0):
self.count = 0
row = self.count * 16
features = self.X.iloc[row:row+16,:]
label = self.y.iloc[self.count,0]
features = torch.tensor(features.values)
label = torch.tensor(label)
self.count += 1
return features, label
I couldn’t use the idx iterator of the Dataset Class for the rows, since when reaching idx = 5, the row value would have been 5 * 16 = 90 which doesn’t exist in my DataFrame.
Hence, I used another counter which resets everytime I reach the 4 iterations.
In this way, the batch_size value I set below must be at most equal to the number of videos I have in my CSV.
As for the label value, everytime, I am choosing the corresponding label associated with the row:row+16 features.
This is then, my training loop, knowing that trainingX and trainingY are the CSVs I wrote above (validationX and validationY have 2 videos):
# Dataloaders
batch_size = 4
# Datasets
train_set = DeepFakeDataset(trainingX, trainingY, batch_size)
val_set = DeepFakeDataset(validationX, validationY, batch_size)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=False)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
trainLosses = []
trainAccuracies = []
valLosses = []
valAccuracies = []
epochs = 100
model = LinearModel().to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
for epoch in tqdm(range(1, epochs+1), leave=True):
model.train()
index = 0
indexV = 0
num_correct_train = 0
num_correct_val = 0
for i, data in tqdm(enumerate(train_loader), leave=False):
vid, label = data
vid = vid.to(device)
label = label.to(device)
optimizer.zero_grad() # We empty the gradients
ypred = model(vid)
# We perform a Binary Classification Entropy Loss with Logits between the real value and our prediction
lTrain = criterion(ypred, label.float())
lTrain.backward() # We compute the gradients
optimizer.step() # Parameters updated -> Single step optimization
# We round the prediction and:
# if == ground truth -> Correct prediction
# if != ground truth -> Wrong prediction
ypred_tag = torch.round(torch.sigmoid(ypred))
num_correct_train += (ypred_tag == label).sum().float()
index += 1
model.eval()
for i, data in tqdm(enumerate(val_loader), leave=False):
vid, label = data
vid = vid.to(device)
label = label.to(device)
ypred_ = model(vid)
# We perform a Binary Classification Entropy Loss with Logits between the real value and our prediction
lVal = criterion(ypred_, label.float())
# We round the prediction and:
# if == ground truth -> Correct prediction
# if != ground truth -> Wrong prediction
ypred__tag = torch.round(torch.sigmoid(ypred_))
num_correct_val += (ypred__tag == label).sum().float()
indexV += 1
train_loss_epoch = lTrain.item()
trainLosses.append(train_loss_epoch)
val_loss_epoch = lVal.item()
valLosses.append(val_loss_epoch)
train_acc_epoch = (num_correct_train/(label.shape[0]*index)).detach().cpu().numpy()
trainAccuracies.append(train_acc_epoch)
val_acc_epoch = (num_correct_val/(label.shape[0]*indexV)).detach().cpu().numpy()
valAccuracies.append(val_acc_epoch)
if (epoch % 10 == 0):
print(f'\nEpoch {epoch+0:03}:')
print(f'\t- Training accuracy : {train_acc_epoch:.3f} (avg. {np.average(trainAccuracies):.3f})')
print(f'\t- Training loss : {train_loss_epoch:.3f} (avg. {np.average(trainLosses):.3f})')
print(f'\t- Validation accuracy : {val_acc_epoch:.3f} (avg. {np.average(valAccuracies):.3f})')
print(f'\t- Validation loss : {val_loss_epoch:.3f} (avg. {np.average(valLosses):.3f})')
print("=========================================")
I use BCEWithLogitsLoss(), since I don’t have the Sigmoid function at the end of my model. Plus I calculate the accuracy by summing the rounding Sigmoid predictions and dividing them by the total number of samples, which I think is the correct way of doing so.
I have the following results after 100 epochs:
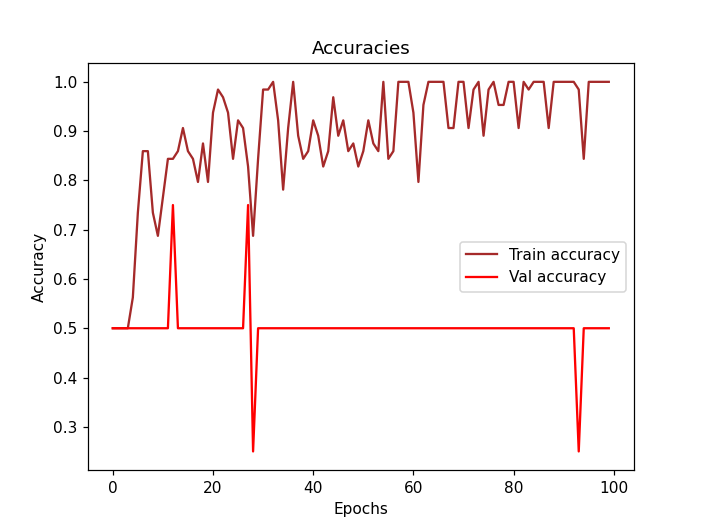
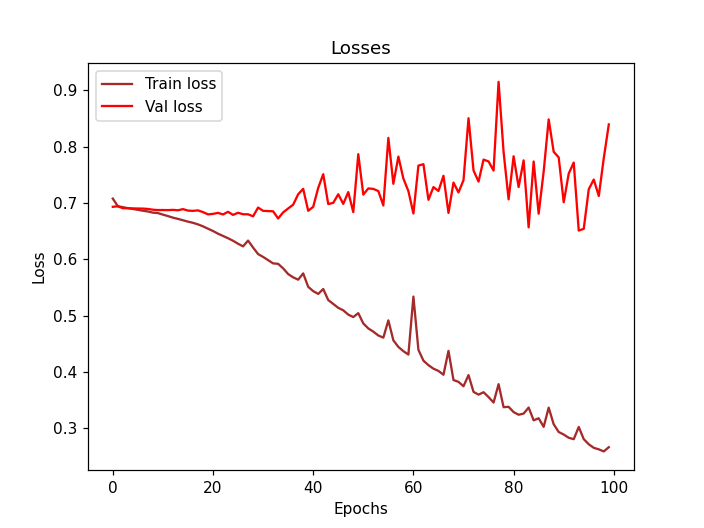
Now, ending this topic, I know that 4 samples might be very very very small, but I want to know if everything is set up correctly, before working on a very bigger dataset.
I want to know if the results I’m having on the validation set (the fact that is constantly 0.5) are a reflection of the overfitting issue or there is something logically wrong in the snippet of code I provided.
Thanks to anyone who had patience to read this. ![]()